 When it comes to innovation and roadmaps there’s nothing special about the start of a new calendar year other than a convenient time to checkpoint the past year and to regroup for the next. Everyone’s feeds are going to be filled with “best of”, “worst of”, and “predictions” for 2016 and those are always fun. What I’ve always found valuable is taking a step back and thinking about the themes that will impact decisions at the product and business level over the next year.
When it comes to innovation and roadmaps there’s nothing special about the start of a new calendar year other than a convenient time to checkpoint the past year and to regroup for the next. Everyone’s feeds are going to be filled with “best of”, “worst of”, and “predictions” for 2016 and those are always fun. What I’ve always found valuable is taking a step back and thinking about the themes that will impact decisions at the product and business level over the next year.
In that spirit, the following is a selection of “hallway debates” that (I think) are sure to occupy the minds of product managers and product leaders over the next year. The hallways can be literal or figurative (i.e. twitter included).
Innovations in 2015
No doubt this year was filled with more than a fair share of “nothing new” or “incremental” views on innovation, but as usual I don’t think that is the case.
The big companies were busy with Watch, iPhone 6S, iPad Pro, Windows 10, Surface Book, HoloLens, Nexus 6P, Pixel C, and more. Amazon delivered an amazing amount of AWS features and capabilities (conveniently listed here). All while this is going on, startups continue to iterate, create new categories, and introduce new technologies (my biased, favorite list is onproducthunt.com every day).
All in all, 2015 was tremendously busy with so many of the products introduced clearly pushing the state of the art.
Musts for 2016
Before getting to the choices that have nuance or subtlety, the following are two top-of-mind factors that get to the heart of building products in 2016. These aren’t debates at all, but creating actionable and measurable plans should be a priority for every team and company.
Diversity and Inclusion
This year, rightfully, brought an overdue and intense focus on the role of diversity and inclusion within leadership, engineering, and businesses in general. The time is right for there to be an exponential change in our approach. We all know this is more than an opportunity, but a necessity. Products are used by an infinite variety of people from all walks of life, backgrounds, and abilities, and it follows that products should be built that way as well.
Looking at this through the lens of rapid change and how working on this early on is so critical, startups need to address this early in a company (and team!) lifecycle or the need to address this dramatically within an existing organization becomes clear. The simple math (and yes this is a simplification) done on this model, highlights just how difficult it can be to catch up if there is just a small and systematic bias along just one dimension (men/women) in an organization.
The discussion needs to happen and from that plans and acting on those plans needs to follow.
Security and Privacy
The run of security breaches in 2015 continued unabated. The damage continues to go up and there seems to be no end in sight to being able to secure legacy infrastructure. There are, however, some good news scenarios.
First, the move to mobile, particularly iOS, and third party SaaS services affords an opportunity to reset the security landscape. Of course these new operating systems are not absolutely secure as we have seen, but the level of security that comes from a new architecture and the investment in up front security places you on much firmer ground. There is no denying this so if you want to be secure, getting more of your use cases to mobile is going to help.
As makers, there are many things that are now part of the first wave of product features that were previously “good to have” features. Start with building on top of existing identity and authentication methods, build all communication channels as encrypted, and encrypt stored data within your own services. Previously these were viewed as enterprise features to be added later or to charge more for, but now these are essential to bootstrapping a service. They are just a start, necessary but not sufficient.
Nearly every discussion about what to purchase or what to build next needs to happen in the context of security and privacy.
Choices for 2016
Product choices are never as binary as we would like — there’s rarely an absolute. In general, there are nuances and more importantly context that drive a particular approach. Therefore, hallway discussions are rarely won (or lost) but are a necessary part of deciding on product strategy.
The best product manager or product leader discussions to have in 2016:
- Invest in Deep Learning
- Bet on Mobile OS
- Ride the Mobile/ARM Ecosystem Wave
- Compute, Not Just View, on Mobile
- Go with Public Cloud
- Choose Platforms Carefully
- Track Computer Science
- Avoid the Bridge
- Create “The Plan” with Quality In Mind
Invest in Deep Learning
This past year has been an incredible year of progress in artificial intelligence or machine learning. Progress has been so significant that the pinnacle of tech leadership has articulated a growing concern of the risks of AI!
Even so, this generation of AI has gone from recognizing cat videos to being able to quickly and easy tag your friends in photo galleries and online services. Nearly every good recommendation engine is now powered by deep neural networks and machine learning.
A couple of great examples of machine learning include visual search at Pinterest and images within Yelp listings. This year even saw Google generate smart email replies for you! These are incredible advances in how problems are solved. The common thread is classifying existing large and labeled data sets within deep neural networks. This contrasts significantly with previous approaches to these same problem areas that would use click streams or other algorithmic approaches.
If you’re still coding recommendations, classifications/labeling, or automated generation of content using algorithms or simple networks, then this is the year to investigate how you would use these maturing approaches. They are all better by leaps and bounds over existing solutions that rely on smaller data sets and algorithmic approaches.
As with every previous AI advance, it is likely that some aspects of these new approaches will be combined with the current state of the art. In particular, the role of existing linguistic solutions will prove incredibly valuable for smaller data sets or difficult to classify solutions for natural language queries or processing in general. Pay close attention to how the research advances though because the role of deep learning for these scenarios is changing quickly.
Bet On Mobile OS
Are tablets turning into laptops? Are laptops turning into tablets? Are tablets losing out to larger screen phones? The permutations of form factors have been dizzying this year. Regretfully, most of this industry dialog is confusing and confused. If you are making client apps, then you could easily get drawn into this confusion and might miss the key decision.
The critical decision point for any new code is to focus on the platform and OS and less on the size and shape of the device. The forward-looking choice is to focus on mobile operating systems: always connected, app stores, touch, security, battery life, and more. These attributes are step function improvements over the x86 platform and given the ongoing investment up and down the stack the gap will only widen. For more on this see a post I wrote “Mobile OS Paradigm”.
Enterprise applications are sure to see a significantly increased level of focus and support on mobile platforms for a number of reasons. First and foremost, the level of security on these platforms is so much improved there isn’t even a debate. Second, enterprise capabilities for managing data landing on these devices continues to improve at a rapid pace and already greatly exceeds all existing approaches. Third, renewed efforts from Apple and Google on enterprise capability enable new scenarios and new approaches.
This topic will continue to generate the debate — “on a phone or tablet, I can’t do everything the way I am used to.” This is a debate that can’t be won and is both a fact and not useful. The reality is that the style and products of work are rapidly changing and so are the tools to support work. Ask yourself a simple question, which is how often do you reach for your phone even when you’re sitting at a desktop or when a laptop is nearby? The more you do that the more that everyone will be making an effort to make sure important stuff happens on that mobile OS.
A large number of workloads will continue, “forever”, to be laptop/desktop centric, starting with software development itself. We’re 30 years into the PC and server revolution and many workloads still happen on mainframes (or with printers or desktop phones). The presence of some scenarios does not invalidate forward-looking decisions. It takes a very long time for an installed base of something to drop to zero.
Ride the Mobile/ARM Ecosystem Wave
The iPhone 6S launched with a new ARM chipset designed by Apple and manufactured by both Samsung and TSMC, along with a wide range of components almost none of which are single sourced. While this is the result of excellent work by Apple it also speaks to the incredible strength of the the ARM/Mobile ecosystem. By any measure, the ability to deliver tens of millions of devices sourcing so many incredibly advanced components from so many vendors is unprecedented.
One of the milestone advances this year was the hardware capabilities of the iPad Pro. The compute performance of this iOS-based tablet exceeds the mainstream laptop. The most striking of the gains came in mobile graphics which are likely to remain a firmly established leadership position. Those clinging to the last generation were quick to point out that there are more powerful devices available or that the software doesn’t allow the same capabilities to shine through. Clearly that is a short-sighted view given the level of investment, number of players, and OS innovation driving the mobile ecosystem.
Such innovation can be mostly transparent to software developers. If you are, however, building hardware or looking to innovate in software using new types of sensors or peripherals then betting on the ARM ecosystem is ano-brainer. The internet-of-things revolution will take place on the ARM ecosystem.
The ecosystem will be on display in full force at the Consumer Electronics Show as it always is each year. We will see dozens of companies making similar products across many industries (the first stage of the Asian supply chain at work). Take note of what is released and you will see the ingredients of the next wave of devices. Integrating multiple devices from a hardware perspective or building innovative cloud services will prove to be great ingredients for new approaches.
Compute, Not Just View, on Mobile
Given the innovation taking place in the ARM/mobile ecosystem, it is fair to ask “what should we do with all this capability?”
The first 10 years of the smartphone apps could be characterized by trying to squeeze the vast capabilities of a cool web service into a tiny screen. With larger screens and innovations in user interface we’re seeing more done in apps. Now with so much more compute and storage on mobile devices we should see innovation in this dimension.
There are many scenarios where the architecture of roundtripping to a server is both slow and costly. The customer experience could be improved with the use of device-side compute or caching on the device.
To illustrate this point consider spell or grammar checking (something which most people don’t implement themselves so it makes a good example). Before connectivity, dictionaries (or rules) were authored by humans and installed locally on devices and rarely updated (how often does language change?) but speedy. The internet showed us that language usage and terms change frequently and spelling in a browser turned to a service with client rendering of results, and high latency along with much better results.
Today the best spelling dictionaries (and suggestions) will be derived from deep learning and training of models on large corpora. Even with great connectivity the latency of a service-only experience is too noticeable. Given the compute on today’s devices, it is not unreasonable to start to see models built on massive data sets packaged up for use locally for specific queries or classifications locally on a device.
This might extend to many examples where learning and models are providing classification or recognition.
Value the Open Source Community as Much as the Code
There is no doubt that the biggest change in software since the internet has been the way open source software now completely dominates the entire industry. By any measure of innovation, open source drives the software that is eating the world.
The not-so-secret ingredient of open source is the community. The community is created from the very start of a project. Early on, the most successful open source projects begin to focus on enrolling the community and creating a shared ownership of both the direction and implementation of the project. You can see this in Github stats around contributors, when people joined and how much they contributed.
Deciding which projects to use in your work should be influenced by the strength of the open source community contributing to a project.
Established companies have benefitted enormously from open source as a foundation, much of that housed within their mass-scale data centers. Recently, many projects which were developed inside companies are being “open sourced” after the fact. This is certainly a positive in many ways, but also offers a different model from what has previously been the most successful.
In contrast to traditional open source projects, these open sourced projects are looking for a community to join in and validate them after the foundation has been built. They are not really looking for a community to shape or influence the project, at least not in ways that will influence what that company sells or offers. Too often it isn’t quite clear how the future of a project will be managed relative to the open sourced code.
It is still early in this new “movement” and worth paying attention. For the time being, joining projects early and/or betting on projects with a genesis as part of an open source community seems to be the best bet. The leaders of any movement tend to people that build, not inherit, projects.
There are companies commercializing existing open source projects. In this case, seeing how those companies continue to contribute to and participate with the community, especially one those founders/individuals created is an easy way to validate a bet on a project. My belief is that the leading companies are created with the leaders that created the project and continue to participate in the evolution. To spark the hallway discussion, check out this post by a16z’s @peter_levine about the uniqueness of RedHat’s success.
Go with Public Cloud
Public cloud or private cloud? To many the answer that sounds best is hybrid cloud — best of both worlds. The lure of the hybrid cloud is incredibly seductive to enterprise customers. The idea that you can get “credit” or “accelerate” the move to the cloud if you just keep some of your existing infrastructure on-prem. The arguments are well-known (data co-location, compliance, etc.) but unfortunately they are never made relative to the two factors that matter most.
First, there is no real “architecture” for a hybrid cloud — the very nature of the cloud is a new way to build and scale applications.
Second, the time and effort to create such an architecture and the complexity introduced all but guarantees building a one-off system that will only grow increasingly harder to maintain, essentially impossible to secure, and then ultimately migrate to a modern cloud.
This is not a semantic debate or a debate of “pure cloud”, but an architecture that is fairly concrete. The cloud is a public cloud and it is far more than easy to create virtual machines in a data center (aka a private cloud). Even if you’re using a public cloud, it is important to consider what your architecture or runtime look like relative to scale — simply moving your VMs to another data center isn’t a cloud either.
From your (potential) customer’s perspective, the arguments for either a private cloud (which isn’t really a cloud) or to simply avoid a public cloud are well-worn and simply not compelling. Security, scale, cost and more all tip in favor of the public cloud without any debate. In almost every regulated environment that touches the internet, the practical view of saying no to the cloud is making less and less sense. It is still going to be important to build that hallway feedback loop from the customer to the product team to make sure you’re well-versed in this dialog and focused on winning the right customers.
If you’re building enterprise software then you’ve already been wrestling with the cost, complexity, and relative difficulty of a customer offering with a consistent, scalable, manageable, and secure on-prem solution. Some will deliver this, but that will not be the norm and enterprise customers should not expect (or want) this from every vendor.
The cloud is not a call to migrate the largest legacy systems, but how to think about new systems and innovating on top of existing systems. That’s the best way to navigate this debate and to build forward-leaning products and services.
If an enterprise is constrained in such a way as to believe it can’t move or create a public cloud then by far the best approach is to avoid investing in a hybrid or “private” approach and stay on the current course and speed until you can invest what is needed.
Choose Platforms Carefully
Everyone building an app or a site wrestles with the platform choice, which has two challenges.
First, everyone with an app wants to make sure it can be used by anyone from most any device.
Second, an app is great but quite a few people (along with enterprises) want to use it from their desktops. In the meantime, doing a great job scaling the product, adding features to win deals, and staying ahead of competition are taking all your time.
The siren song of cross-platform will continue unabated this year. The ability to deliver a winning experience from a single code base targeting increasingly divergent mobile platforms will continue to prove elusive (and the presence of an exception or two does not make it any more possible). As with past transitions and even some current efforts, getting the first bit done can lead one to believe that you’ve found the magic and it can work. This too is part of the pattern of cross-platform. Over time, an increasingly short time due to rapid platform evolution, the real-world catches up with even the best efforts. There’s more on this topic here.
The main mobile platforms are innovating in ways that do not have symmetric or analogous capabilities: the rise of the Swift language, the diverging user interface models (voice, multi-app models), the changing hardware landscape (force touch, tablet sizes and resolutions), and platform services (payments, identity, service integration).
This only leaves one viable, long-term option for any mobile app that is key to the overall value equation, which is to manage platform efforts as dedicated and separate teams. Managing this is always expensive and often complex. The key is how product managers lead the choice and execution of shared features and platform specific features.
As if this isn’t enough, some set of enterprise tools are seeing demand for apps on the desktop that go beyond browser apps. A number of mature enterprise efforts have started to deliver App Store or downloadable traditional desktop apps in addition to the browser. The implementation of these has consistently been to wrap the browser version in a native frame window and use an embedded webview for the app. This affords some base integration such as convenient app switching, window management, and persistent logon. Few offer any in-depth desktop OS integration and most still remain behind the browser in key capabilities (drag and drop for example). This is especially true if the primary use case is running across multiple browsers given the effort to maintain consistency in those implementations.
The real versus perceived value of these webview based solutions is debatable. The resources required and the implied long-term commitment to customers are not. In addition, the implementation choice leaves little room for true desktop integration. Unless you’re willing to commit to building a native experience, it isn’t clear that the investment for these apps represents the best way to win or stay ahead in the marketplace.
Track Computer Science
Some of the most interesting startups are those coming out of university or industry research laboratories with open source projects or those bringing entirely new approaches to what are traditionally “well-understood” computer science fields. It has been a long time since so much of what is new and interesting also happens to be the newest and most interesting topics being researched by new graduate students in university research labs.
Innovation tends to come in waves where whole new ideas take shape and then for a “generation” those ideas are executed on to the n-th degree. A classic example of this is the relational database model, SQL. Born out of IBM’s industrial labs (in what is no doubt a whole other era in corporate labs) and then iterated upon at the database layer by IBM, then Oracle, then many others. It created an industry of tools and products, along with perhaps the largest community of those skilled in the core SQL concepts. Today we have a whole new generation of database technologies all of which have their roots in research labs around the world.
Deep learning has roots in research labs and is now on a very fast pace to broad commercialization. Virtual reality and augmented reality approaches build on a wide array of computer science inputs.
All of this is a way of saying that your hallway discussions and debates this year should include computer science. Track the conferences. Read the summaries. Dig into the papers. Even if you’ve been out of school for a while or never really thought the research world was all that practical or interesting, my view is that we’re in the part of the cycle where there is much to learn by paying attention.
Avoid the Bridge
The hardest product choices remain those to be made by enterprise products. Where as the consumer world it is almost always about moving forward, being new, and building on the current, the enterprise world always has to balance the installed base, legacy, or compatibility. All too often the inertia behind the choices already made actively prevents forward looking choices that are inherently disruptive (disruptive in the dictionary sense as well as in the Silicon Valley sense).
The natural outcome of this is a bet on a transitionary period or a bridge technology — the enterprise world embraces such approaches to no end. Unfortunately, history has consistently shown that bets on the bridge not only fail to bridge to a new world, they ultimately prevent you from fully participating in this changes. Even more challenging, is that during the next technology wave you find your product an additional generation behind and an even bigger challenge. This goes beyond shiny new technologies simply because right now whether you build client code, create services or APIs, install infrastructure, or build and analyze data we are in the midst of an exponential rate of change relative to all of those. When you miss a beat during exponential change you simply can’t catch up — such is the power and challenge of that pace of change.
As a result, it is these “bridge” or hope for the “best of both worlds” topics lead to the most challenging hallways conversations. The hope here is to push in the direction of forward, bringing some comfort to those leaving the well-worn and understood past behind.
Create “The Plan” with Quality In Mind
Product management is constantly trying to get more done, in less time, with fewer resources. No one wants to move slow, get mired down in some big company planning effort, or worse fall behind competitors. That’s a given. It is also nothing new.
For quite some time now we as an industry have been on a bit of a roller coaster when it comes to how to plan what to work will get done. At one extreme the whole idea of having a plan was effectively shunned in favor of minimally viable products (a valuable concept often misapplied to mean, “toss it out there”) or in favor of putting something out and then letting failure determine what comes next. The other extreme essentially created a process out of reacting to data — the plans for what to do were always informed by what was going on with the live site or testing of changes to existing products.
This past year is one marked by failures of quality execution by even the biggest companies. You would have to look hard to find companies that made significant product changes without also receiving some (sometimes significant) critical feedback on the quality (robustness) of execution. Apologies, commitment to “less features, more quality”, and fast revisions/reversions seemed to be the norm this year.
At the same time there appears to be a bit of decommit from the discipline of testing. In my view this is more semantic than reality given that the work of designing, building, and running tests still needs to get done. The jury is still out on this and I’m personally not convinced that software is ready to be free of a QA discipline.
One could view this as a pendulum, but in practice this is the price our industry pays to work at planetary scale. It might be the case that your product is used only by early adopters and tech enthusiasts, but those very people are having their quality bar set by the broader industry benchmarks.
Quality is the new cool. Releasing without the need to re-release is the new normal. Testing is the what’s old is new again.
When you’re having the debates about what to get done and when, this will be a year where deciding that getting something done right, done well, should trump getting something done today or halfway, or getting something done that you know isn’t right (in a big way).
You do not/should not need to revert to a classic “waterfall” (a term applied with disdain to any sort of planful process). However, some level of execution rigor beyond the whiteboard is the kind of innovation product management should bring to the table this year. There’s no reason that products can’t work very well when they are first released, even when you know there is much to be done. There’s no reason you can’t have a product plan and a roadmap at a useful level that is written down, without it being a burdensome or overly-structured “task”.
At the risk of self-reference, two posts on these topics from this past year I’d leave you with: Beauty of Testing and Getting (the Right) Stuff Done.
 In
In 
 Much is being said lately about the trend to unbundle capabilities for the web and apps. Is this a new trend, a pendulum, or another stage in the evolution of providing software solutions for work and life? Are we going to learn what some would say are lessons from a past generation of software and avoid bloatware? Perhaps we will relive some of the experiences from that era and our phones and tablets will be littered with app shrapnel as our PCs once were?
Much is being said lately about the trend to unbundle capabilities for the web and apps. Is this a new trend, a pendulum, or another stage in the evolution of providing software solutions for work and life? Are we going to learn what some would say are lessons from a past generation of software and avoid bloatware? Perhaps we will relive some of the experiences from that era and our phones and tablets will be littered with app shrapnel as our PCs once were? Designing a user experience for many millions of people is a unique job that a relatively small number of people practice. The responsibility of such an undertaking is immense, stressful, and one that can be all-consuming. Cold sweats, sick to your stomach, and a constant feeling of messing up are the norm for those that take on these challenges.
Designing a user experience for many millions of people is a unique job that a relatively small number of people practice. The responsibility of such an undertaking is immense, stressful, and one that can be all-consuming. Cold sweats, sick to your stomach, and a constant feeling of messing up are the norm for those that take on these challenges.
 Innovation and disruption are the hallmarks of the technology world, and hardly a moment passes when we are not thinking, doing, or talking about these topics. While I was speaking with some entrepreneurs recently on the topic, the question kept coming up: “If we’re so aware of disruption, then why do successful products (or companies) keep getting disrupted?”
Innovation and disruption are the hallmarks of the technology world, and hardly a moment passes when we are not thinking, doing, or talking about these topics. While I was speaking with some entrepreneurs recently on the topic, the question kept coming up: “If we’re so aware of disruption, then why do successful products (or companies) keep getting disrupted?”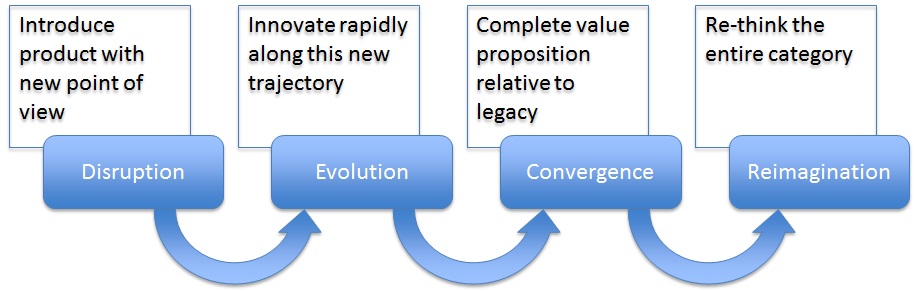

 This post is about a discipline (or sometimes called function-based) org structure. Like many management “principles”, org structures represent a pendulum that swings back and forth between ends of a spectrum. In this case the ends are usually characterized as a discipline structure or a product / product line / business structure. In practice things are more nuanced than these end-of-the-spectrum descriptors.
This post is about a discipline (or sometimes called function-based) org structure. Like many management “principles”, org structures represent a pendulum that swings back and forth between ends of a spectrum. In this case the ends are usually characterized as a discipline structure or a product / product line / business structure. In practice things are more nuanced than these end-of-the-spectrum descriptors.

