Posts Tagged ‘enterprise’
A Product Person’s Perspective on Enterprise Selling
An architectural diagram for enterprise selling. ↗️
Many of the technical founders I have the opportunity to work with are well-versed in the architecture and features of their products (and products in general), but when it comes to possessing a similar view of the sales process there’s a good chance they are staring at a blank whiteboard. That’s to be expected because the skills and experience to do enterprise sales, and to do it well, are earned in the trenches over many years. Selling, specifically enterprise selling, is not something that comes naturally to most product-minded people.
Note: This post originally appeared on a16z.com on May 20, 2015.
Just as with code, one can devise an architectural view of how enterprise selling works. And like code, it is best to approach the process of selling using an architecture, rather than just diving in and writing code. Unlike code, if you act in haste or otherwise squander an enterprise opportunity there’s not really a chance for a rewrite or undo so it is best to approach with caution. Of course I’ve made many of my own mistakes and have also had ample time to learn what it was I have done wrong or what invalid assumptions I held. This post is a framework to help make sense of all the motions and actions that go on in the scope of enterprise sales.
Most technology leaders are consistently amazed at the depth and sophistication in enterprise selling. Since most engineers or technologists have little experience big-ticket selling, other than perhaps buying a car, this isn’t a surprise. While you might not be a designer or engineer, as a product person you have an empathy or sense of the skills, roles, and processes used. The same usually can’t be said for sales and selling.
There’s really only one key factor that distinguishes enterprise selling from everything a product person knows, and that is enterprise selling ends with the product and starts with the enterprise. Of course that is the complete opposite of what one might normally think where everything starts with a product. Even with the most amazing and inventive product ever conceived, selling at the enterprise level and enterprise scale requires inverting your perspective. There’s an analogy many often understand. Most product people know you don’t build a product by starting with a specific technology just because it is new, cool, or novel. Rather one starts by solving a problem of some sorts where applying a technology creates an amazing new experience that addresses a need or solves an articulated problem. Enterprise sales is similar in that you don’t start with a solution (your product) and then get to the problem (customer need, articulated or not).
Enterprise selling ends with the product and starts with the enterprise.
There are tons of amazing resources on enterprise selling. Resources go from the specifics of sales motions for a single sales person all the way to models for setting quotas, organizing resources, and training the sales organization. Most every seasoned enterprise sales person has their favorite toolset and part of hiring and managing a team is empowering them to make use of the tools they are comfortable with (just like you would for engineers). One resource I value is the book SPIN Selling, which is sort of a classic and spawned a whole ecosystem of supporting tools and guides.
A framework for product people
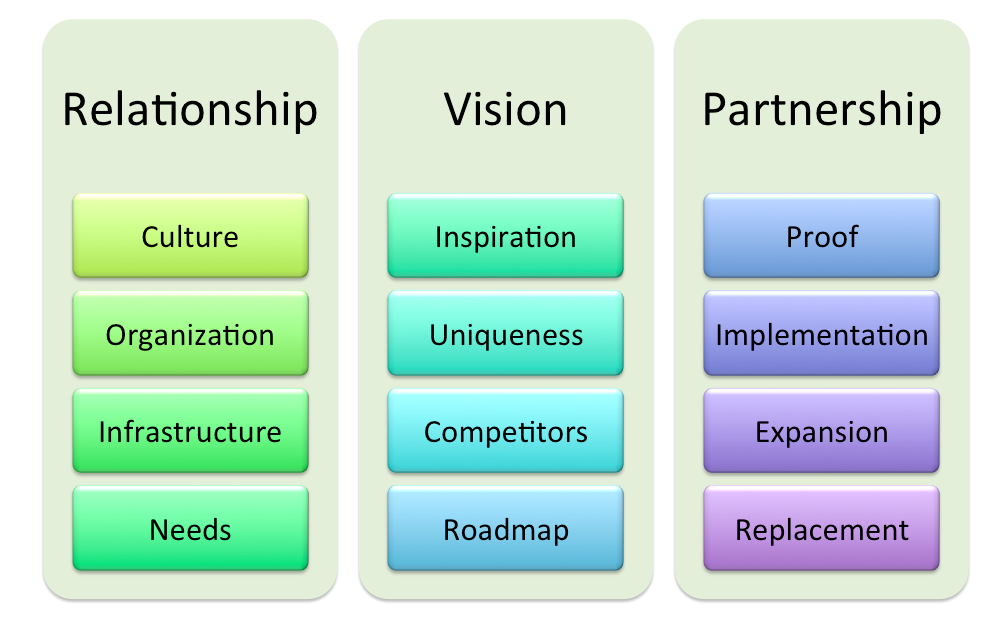
At an abstract level you can think of enterprise selling as following three steps:
First you set out to build a relationship with the enterprise customer that rests on a foundation of a deep understanding of their unique context. This relationship is formed by learning about the customer and organization, including how they do what they do, what they are struggling with and where they are heading. The biggest risk in most enterprise sales cycles is assuming you know these things—that one bank is like any other bank, that all Oracle shops are similar, or that everyone is trying to rip out SAP or move to the cloud. Almost all failures in enterprise selling, or at least all deal closing crisis moments, are caused by rushing this step or failing to learn all that needs to be learned about an enterprise.
Second, you articulate your vision or view of the “world” and how given your understanding of the enterprise you can begin to talk about a view for how to add value to an organization. The notion of “adding value” is key to this dialog as “solving problems” can set you up to fail too early in the process. The reason for this is that enterprise IT knows all to well that any new system begins with sunk costs, reduced productivity, and in general a period of investment. All this happens before the return or value is brought to the enterprise.
Finally, the last step is to establish a partnership, based on a mutual understanding. You understand the enterprise. The enterprise understands how you aim to aid value to their organization. The partnership process itself is how you go about going from pilot to implementation to expansion, sometimes called land and expand.
Let’s dive into each of these briefly with the goal of offering a flow or outline of the sorts of actions and motions that should take place. It is worth emphasizing that there’s a lot of unique value in how a given enterprise account manager approaches a specific customer with a specific type of product — so I’m not implying this is a one-size-fits-all model.

Relationship
The goal of the first milestone is a strong understanding of what things are like within the enterprise you are selling. To a product person this is very similar to those first ideas in developing a product-market fit and needing to assess the potential for the market. Much of the early effort will be consumed by understanding if you’re even working with the right team or people within an organization, and often there are multiple parties. Too often a product person believes you start at the CEO and shortcut this step, but an experienced account manager knows great deals can die in the middle of an organization just as easily at the top.
Culture. First you want to understand a bit of the culture of the enterprise. How risk averse they might be (for example, where do regulations fit or how leading edge is the organization as a whole)? You want to understand a bit about how decisions are made and how technologies and products are evaluated. You want to make sure you are sensitive to the basics of how the company likes to do business (how formal, what times do meetings take place, where do coffee, meals, drinks fit or don’t fit, and so on). This is especially true as you venture to industry segments that are unfamiliar to you. If you’ve ever done business in a different country before a good mindset to get in is to treat the initial contacts with an enterprise with the same level of cultural sensitivity and learning—better to learn rather than assume when you’re in an unfamiliar environment.
Organization. Every enterprise sales person I have worked with begins to build out the physical and logical org chart from the first engagements. You want to learn the management reporting structure as well as the power You want to understand the budget and decision making processes. Great enterprise sales people also know that you invest in the full org chart and don’t just focus on the areas of most authority and power—you never know where an advocate or obstacle might appear from as a deal progresses.
Infrastructure. IT is all about infrastructure and understanding how the company really works will be key to speaking their language. Not only are all enterprises subtly different in infrastructure, they take great pride in the differences they maintain and the rationale behind those differences, no matter how odd or crazy they might seem. I remember once pitching Office to an enterprise customer that had customized the installation of Office uniquely for over 100 different job functions. Not only did I think this was nuts, it created a massive support burden for the company. But in their world this was key to their productivity and my job was not to “save” them but to show them how I made their job even easier with a new product (all that comes later, in this step you’re just learning). You need to understand all the basics of infrastructure from authentication, networking, BYO, approved apps, messaging, email, and more many of these environmental variables will almost certainly impact your solution’s applicability and deployment.
Needs. Once you understand the culture, organization, and the technical infrastructure you have the foundation to be able to understand the enterprise’s needs. This is often the trickiest part of the first phase because it turns out enterprise IT, even though they are experts in technology, most often express their needs in terms of their own understanding or expectations of what products can do. As you catalog and understand needs what you are really doing is learning how to bridge from the solution your advocates believe they want to a solution that might be a much bigger leap (and much better, but very different) than expected. The pressure to listen to customers and act directly on needs (often described as requirements) is intense and during the course of product development and sales will be a significant challenge to just about every company.
My earliest days working with enterprise customers taught me a lesson that I have to admit still makes the “here and now” product person in me a bit uncomfortable. It was told to me by a former IBM field sales engineer who said “I sold more product today based on selling the future product than I ever sold by just selling what was ‘in my bag’.” While that’s most decidedly a cynical view, the reality is that enterprise selling is never about what a product can do right this moment—that’s just practical given the purchase, deployment, and training cycles within a large organization. Therefore a huge part of enterprise selling is articulating your unique technology/world view in the context of the relationship you have developed.
Vision
To many this can sound like selling vaporware, an old term for software that never shipped. That isn’t true at all. This is about selling a broad concept that will both endure for years and take years to fully realize, but can start delivering ROI in the near term within a known time period and cost. Putting this in the context of startups, this is much like when you hear venture capitalists talking about the investment in the team relative to the idea or invention—everyone knows the maze from idea to product to business will change and scope the initial idea, but the bet on the team and people will endure.
Inspiration. What is your inspiration for the product? This is where you talk about the experience that led you rethink the landscape. In the enterprise space this is most often about revisiting assumptions that the industry has made about costs of technology, where there is hardware versus software, or some massive shift such as the move to mobile or the cloud. Relative to a startup, you can think of this as the founder’s story—what led the founder to start a company is very much in line with what inspired the creation of a new enterprise product or service.
Uniqueness. While your inspiration is important it is likely that may people will have the same inspiration. In fact, enterprise products often appear in waves when it appears as though many are doing the “same” thing all at once. If you are in enterprise IT, then for sure every single vendor meeting you have these days is about cloud, mobile, BYO, security, and more. In a sales motion, you don’t want to spend a lot of time being the umteenth person touting the “changing world” but want to quickly articulate the insight, secret ingredient, or radical implementation that you have that you believe is unique. Too often this can be viewed as marketing, but really this needs to come from your product core—what is it that you see that no one else sees (to paraphrase Peter Thiel). Building a better mousetrap is great, but ROI in the enterprise does not come from rip and replace getting you a 10% improvement, so your inspiration should be pretty significant.
Competitors. You are not alone. No one in enterprise IT believes you built the one and only product that does most of what you do. Coming to an enterprise sales engagement with a detailed understanding of competitors shows respect and acknowledgement of reality. There are two types of competitors you need to understand fully. First, you need to be versed in the current marketplace competitors and how you compare to them. Often the best tool to view this is a classic “magic quadrant”—just be forewarned you have to substantiate claims carefully and be prepared for the “fans” of competitors to confront you (and be prepared for your competitors to sell against your characterization). If you’re doing this right, you are not creating new comparison criteria but using incumbent/competitor criteria as a starting point. Second, you need to be versed in how the enterprise is already addressing (or trying to address) the problem space. This is just as much a competitor—in enterprise software the easiest product to buy is the one you’ve already got in place and no one gets fired for doing that. While you might be negative towards your market competitors, it is incredibly important to be respectful of implemented competitors or homegrown solutions even if some in IT might mock their own choices.
Roadmap. The key deliverable for a vision is your roadmap of where you are heading. A roadmap to a product person might look like a schedule and features and some in IT most certainly would love that sort of information. In practice, the sort of tool you want to employ is much less detailed and granular than a product roadmap. Instead, you want to use a roadmap to establish a credible view for how you intend to both refine your existing proposition and expand your solution space. Why is this so critical? Enterprise IT is all about planning and long term within the organization. Budgets, headcount, organization, and internal service relationships all depend on “knowledge of the future”. At the same time, IT also wants to build new capabilities within the company and your roadmap can become a part of the IT roadmap. Obviously everything here is a fine balance between “promise and deliver” and falling into the trap of “over-promise and under-deliver”. One personal example was the introductions of both Outlook and Sharepoint and how adding them to the roadmap caused significant consternation in how IT thought of Office, which then crossed from personal productivity to messaging and then server infrastructure. In hindsight, the introduction of a product literally brought together parts of IT that previously never worked together!
Partnership
Transport yourself a couple of months (!) from that first opportunity to meet a potential customer and you’ve got a chance to really start to sell a product. For most product people, this is about deployment but to an enterprise account manager this last phase is about building a partnership. There is a distinction. The goal is to become long term partners and the tactic is to get the software into deployment and usage, not the other way around.
This phase always takes a bit longer than expected and for the first customers of a new product is a great deal of collaboration between engineering and sales. In later stages this repeatable process tends to become the role of Customer Success. For early stage products and companies, this phase is the equivalent of product-market fit as you work with the customer to refine the product (and pricing and more).
Proof. The first step is literally a proof of concept. The goal is to get the product up and running in their environment which could be as simple as single-sign on or a few dedicated clients or as complex as deployment or an isolated network with server hardware. It is likely during this stage that you will need to gain access to data, users, and systems that make the proof more relevant. It is important to be flexible and patient because for many pilots this is the most frustratingly slow part of the process. Do keep in mind, most every IT organization routinely does dozens of PoC, proof of concept, deals a year across many departments so be careful not to count this as “done” but do count it as “success”.
Implementation. The implementation phase is the time when you go from PoC to a deployed solution, aka production, within a department or company. For those building their first enterprise product, they are often shocked at how long it takes to roll out a new service or system within an enterprise even after it is running and working. We often compare this to signing up for a new SaaS service when in reality most companies are filled with employees that are far more worried about failing to get their work done than they are excited to try new tools and change the way they work. While many think most of the learning happens during the PoC, the astute enterprise product person knows that the real learning and informing of future product features takes place during the phased-in implementation when the product is in use by a wider audience outside of IT (if applicable).
Expansion. From a business perspective, the implementation counts as “land” and the next step is to “expand”. Once you’ve landed and seen early success, your advocates within IT will want to explore different ways to expand—remember IT is like everyone else and when something goes well they want to get credit and get visibility for the solution. Expansion is really the accelerator for a business and as most experienced people will tell you, there’s almost always more revenue with customers already paying you than with starting all over again with new potential customers. Enterprise products should be equipped in both the business and the product to expand in depth and breadth of usage to maximize this phase of growth. There’s potential for a bit of friction here as sales wants to keep the price down and not partition product value in order to land the deal. Management incentives across sales, marketing, product, and engineering play a critical role in finding this balance.
Replacement. The very last step in the partnership with an enterprise customer is replacing an existing system. I purposely put this last because most every product person thinks that when you have a new product the first line of sales is to explain what the customer can replace or decommission if they buy the new product. Every IT person knows that this is exactly the very last thing you do and that the long tail on usage for any implemented system before actual replacement, no matter how inevitable. This is important to internalize in terms of building a partnership because every running system has a champion or advocate who bought and deployed the system so a poor selling technique is to challenge that person too early. If you play everything correctly, someday you will be the system that keeps running long after it should—that’s something to keep in mind!
* * *
If all of this seems like a lot of work and a great deal of calendar time, well then you read it correctly. Average enterprise sales cycles for seven figure sales are easily 3 months and often up to 9 months depending on pre-existing systems. While every once in a while there are shortcuts or magical products, by and large this is how enterprise selling goes. It also makes a lot of sense because you’re going to collect a lot of money every year and your product will become an important part of a business.
Mobile OS Paradigm

Cycle of nature of work, capabilities of tools, architecture of platform.
Are tablets the next big thing, a saturated market (already), dead (!), or just in a lull? The debate continues while the sales of tablets continue to outpace laptops and will soon overtake all PCs (of all form factors and OS). What is really going on is an architectural transformation—the architecture that defined the PC is being eclipsed by the mobile OS architecture.
The controversy of this dynamic rests with the disruptive nature—the things that were easy to do with a PC architecture that are hard or impossible to do with a mobile OS, as well as the things in a mobile OS that make traditional PCs seem much easier. Legacy app compatibility, software required for whole professions, input preferences, peripherals, and more are all part of this. All of these are also rapidly changing as software evolves, scenarios adapt, and with that what is really important changes.
Previous posts have discussed the changing nature of work and the new capabilities of tools. This post details the architecture of the platform. Together these three form an innovation cycle—each feeding into and from each other, driving the overall change in the computing landscape we see today.
The fundamental shift in the OS is really key to all of this. For all the discussed negatives the mobile OS architecture brings to the near term, it is also an essential and inescapable transition. Often during these transitions we focus in the near term on the visible differences and miss the underlying nature of the change.
During the transition from mini to PC, the low price and low performance created a price/performance gap that the minis thought they would exploit. Yet the scale volume, architectural openness, and rapid improvement in multi-vendor tools (and more) contributed to a rapid acceleration that could not compare.
During the transition from character-based to GUI-based PCs many focused on the expense of extra peripherals such as graphics cards and mice, requirement for more memory and MIPs, not to mention the performance implications of the new interface in terms of training and productivity. Yet, Moore’s law, far more robust peripheral support (printers and drivers), and ability to draw on multi-app scenarios (clipboard and more) transformed computing in ways character-based could not.
The same could be said about the transition to internetworking with browsers. The point is that the ancillary benefits of these architectural transitions are often overlooked while the dialog primarily focuses on the immediate and visible changes in the platform and experience. Sometimes the changes are mitigated over time (i.e. adding keyboard shortcuts to GUI or the evolution of the PC to long file names and real multi-tasking and virtual memory). Other times the changes become the new paradigm as new customers and new scenarios dominate (i.e. mouse, color, networking).
The transition to the mobile OS platforms is following this same pattern. For all the debates about touch versus keyboard, screen-size, vertical integration, or full-screen apps, there are fundamental shifts in the underlying implementation of the operating system that are here to stay and have transformed computing.
We are fortunate during this transition because we first experienced this with phones that we all love and use (more than any other device) so the changes are less of a disconnect with existing behavior, but that doesn’t reduce the challenge for some or even the debate.
Mobile OS paradigm
The mobile OS as defined by Android, iOS, Windows RT, Chrome OS, Windows Phone, and others is a very different architecture from the PC as envisioned by Windows 7/8, Mac OS X, Linux desktop. The paradigm includes a number of key innovations that when taken together define the new paradigm.
- ARM. ARM architecture for mobile provides a different view of the “processor”: SoC, multi-vendor, simpler, lower power consumption, fanless, rich graphics, connectivity, sensors, and more. All of these are packaged in a much lower cost way. I am decidedly not singling out Intel/AMD about this change, but the product is fundamentally different than even Intel’s SoCs and business approach. ARM is also incompatible with x86 instructions which means, even virtualized, the existing base of software does not run, which turns out to be an asset during this change (the way OS/360 and VMS didn’t run on PCs).
- Security. At the heart of mobile is a more secure platform. It is not more secure because there are few pointers in the implementation or fewer APIs, but more secure because apps run with a different notion of what they can/cannot do and there is simply no way to get apps on the device that can violate those rules (other than for developers of course). There’s a full kernel there but you cannot just write your own kernel mode drivers to do whatever you want. Security is a race of course and so more socially engineered, password stealing, packet sniffing, phone home evil apps will no doubt make their way to mobile but you won’t see drive by buffer overrun attacks take over your device, keystroke loggers, or apps that steal other apps’ data.
- Quality over time and telemetry. We are all familiar with the way PCs (and to a lesser but non-zero degree Macs) decay over time or get into states where only a reformat or re-imaging will do. Fragility of the PC architecture in this regard is directly correlated with the openness and so very hard to defend against, even among the most diligent enthusiasts (myself included). The mobile OS is designed from the ground up with a level of isolation between the OS and apps and between apps that all but guarantee the device will continue to run and perform the way it did on the first day. When performance does take a turn for the worse, there’s ongoing telemetry that can easily point to the errant/causal app and removing it returns things to that baseline level of excellence.
- App store model. The app store model provides for both a full catalog of apps easily searched and a known/reviewed source of apps that adhere to some (vendor-specified) level of standards. While vendors are taking different approaches to the level of consistency and enforcement, it is fair to say this approach offers so many advantages. Even in the event of a failure of the review/approval process, apps can be revoked if they prove to be malicious in intent or fixed if there was an engineering mistake. In addition, the centralized reviews provide a level of app telemetry that has previously not existed. For developers and consumers, the uniform terms and licensing of apps and business models are significant improvements (though they come with changes in how things operate).
- All day battery life. All day battery life has been a goal of devices since the first portable/battery PCs. The power draw of x86 chipsets (including controllers and memory), the reliability challenges of standby power cycles, and more have made this incredibly difficult to reliably “add on” to the open PC architecture. Because of the need for device drivers, security software, and more the likelihood that a single install or peripheral will dramatically change the power profile of a traditional device is commonplace. The “closed” nature of a mobile OS along with the process/app model make it possible to have all day battery life regardless of what is thrown at it.
- Always connected. A modern mobile OS is designed to be always connected to a variety of networks, most importantly the WWAN. This is a capability from the chipset through the OS. This connectivity is not just an alternative for networking, but built into the assumptions of the networking stack, the process model, the app model, and the user model. It is ironic that the PC architecture which had optional connectivity is still less good at dealing with intermittent connectivity than mobile which has always been less consistent than LAN or wifi. The need to handle the constant change in connectivity drove a different architecture. In addition, the ability to run with essentially no power draw and screen off while “waking up” instantly for inbound traffic is a core capability.
- Always up to date apps/OS. Today’s PC OSes all have updaters and connectivity to repositories from their vendors, but from the start the modern mobile OS is designed to be constantly updated at both the app and OS from one central location (even if the two updates are handled differently). We are in a little bit of an intermediate state because on PCs there are some apps (like Chrome and Firefox, and security patches on Windows) that update without prompts by default yet on mobile we still see some notifications for action. I suspect in short order we will see uniform and seamless, but transparent, updates.
- Cloud-centric/stateless. For decades people have had all sorts of tricks to try to maintain a stateless PC: the “M” drive, data drives or partitions, roaming profiles, boot from server, VM or VDI, even routine re-imaging, etc. None of these worked reliably and all had the same core problem, which was that whatever could go wrong if you weren’t running them could still go wrong and then you’re one good copy was broken everywhere. The mobile OS is designed from the start to have state and data in the cloud and given the isolation, separation, and kernel architecture you can reliably restore your device often in minutes.
- Touch. Touch is the clearly the most visible and most challenging transition. Designing the core of the OS and app model for touch first but with support for keyboards has fundamentally altered the nature of how we expect to interact with devices. No one can dispute that for existing workloads on existing software that mouse and keyboard are superior and will remain so (just as we saw in the transition from mainframe to mini, CUI to GUI, client/server to web, etc.) However, as the base of software and users grows, the reality is that things will change—work will change, apps will change, and thus work products will change, such that touch-first will continue to rise. My vote is that the modern “laptop” for business will continue to be large screen tablets with keyboards (just as the original iPad indicated). The above value propositions matter even more to todays mobile information worker as evidenced by the typical airport waiting area or hotel lobby lounge. I remain certain that innovation will continue to fill in the holes that currently exist in the mobile OS and tablets when it comes to keyboards. Software will continue to evolve and change the nature of precision pointing making it only something you need for PC only scenarios.
- Enterprise management. Even in the most tightly managed environment, the business PC demonstrates the challenges of the architecture. Enterprise control on a mobile OS is designed to be a state management system, not a compute based approach. When you use a managed mobile device, enterprise management is about controlling access to the device and some set of capabilities (policies), but not about running arbitrary code and consuming arbitrary system resources. The notion that you might type your PIN or password to your mobile device and initiate a full scan of your storage and install an arbitrary amount of software before you can answer a call is not something we will see on a modern mobile OS. So many of the previous items in the list have been seen as challenges by enterprise IT and somewhat ironically the tools developed to diagnose and mitigate them have only deepened the challenges for the PC. With mobile storage deeply encrypted, VPN access to enterprise resources, and cloud data that never lands on your device there are new ways to think of “device management”.
Each of these are fundamental to the shift to the mobile OS. Many other platform features are also significantly improved such as accessibility, global language support, even the clipboard and printing.
What is important about these is how much of a break from the traditional PC model they are. It isn’t any one of these as much as the sum total that one must look at in terms of the transition.
Once one internalizes all these moving parts, it becomes clear why the emphasis on the newly architected OS and the break from past software and hardware is essential to deliver the benefits. These benefits are now what has come to be expected from a computing device.
While a person new to computing this year might totally understand a large screen device with a keyboard for some tasks, it is not likely that it would make much sense to have to reboot, re-image, or edit the registry to remove malware, or why a device goes from x hours of battery life to 1/2 x hours just because some new app was installed. At some point the base expectations of a device change.
The mobile OS platforms we see today represent a new paradigm. This new paradigm is why you can have a super computer in your pocket or access to millions of apps that together “just work”.
–Steven Sinofsky (@stevesi)
Tanium Magic
 Lightning doesn’t often strike twice, but in the case of the father and son team of David and Orion Hindawi, founders of Tanium, Inc., that’s exactly what has happened. Tanium is a prime example of a modern enterprise software company—solving the new generation of today’s problems using skills and experience gained from being successful founders in the previous generation.
Lightning doesn’t often strike twice, but in the case of the father and son team of David and Orion Hindawi, founders of Tanium, Inc., that’s exactly what has happened. Tanium is a prime example of a modern enterprise software company—solving the new generation of today’s problems using skills and experience gained from being successful founders in the previous generation.
Forming the company
David Hindawi, a PhD in Operations Research from UC Berkeley is an entrepreneur who led the creation of several successful companies through the earliest days of the PC era. His early efforts focused on getting PCs connected to the “net” and keeping them running smoothly.
In 1997, David teamed up with his son Orion, then an undergraduate at UC Berkeley, to form BigFix. BigFix solved the problem of communicating with all the end-points (PCs, servers, virtual machines, and more) on enterprise networks to gather configuration data and deploy product updates. BigFix was a remarkable product for the time routinely scaling to 100,000 end-points. In 2010, IBM acquired BigFix and integrated it into the Tivoli Software portfolio marking a successful exit.
Some might have been content to rest on their collective laurels having invented the technology, built a company, and scaled a business to the most elite of enterprise success stories. Instead, David, Orion and the key architects of BigFix had an even bigger idea.
Forming Tanium came about as the team reflected on these product shortcomings. “We recognized that enterprises needed endpoint control that was much faster than they could get with existing tools, and challenged ourselves to leapfrog the state of the art, including BigFix, where basic management queries could take days.” Orion recounted, “We knew that nothing short of a 10,000 times speed improvement over the state of the art at the time would solve the problem, and we needed to fundamentally change the paradigm of systems management and end-point security to accomplish that. We are lucky to have one of the few engineering teams in enterprise management who are smart and ambitious enough to do that”.
The team, mostly members of the original BigFix engineering group and all experts with years of experience in large enterprise management, worked in their Berkeley, CA offices for almost two years before the first customers saw the early results of their new product. When seeing the product in action, it was clear to early customers that the team had in fact built a better mousetrap. Tanium was born.
Meeting Tanium @ a16z
When Orion first came to Andreessen Horowitz to meet us and introduce Tanium we had no idea what a surprise we were going to see. Collectively we are many old hands at systems management and security. Many folks at a16z share the experience of having built Opsware and my own experience at Microsoft make for an informed, and perhaps tough, audience.
Orion popped open his laptop, clicked a bookmark and navigated to Tanium’s web-based “console”. At the top of the screen, we saw a single edit control like you’d see for a search engine. He started typing in natural language questions such as “show computers where CPU > 75%” and “show computers with a process named WINWORD.EXE”. Within seconds, just like using search, a list of computers scrolled by as though it was just an existing spreadsheet or report. At this point we reached the only reasonable conclusion—Orion was showing us a simulation of the product they hoped to build.
After all, we were all quite familiar with the state of the art for this type of telemetry (BigFix in particular represented the state of the art) and we knew that what we were seeing was just not possible.
But, the demonstration was not a simulation or edited screen capture. In fact, Tanium was running on a full scale deployment of thousands of end-points. This wasn’t even a demo scenario, but a live, production deployment—the magic of Tanium. As we learned more about Tanium and how it easily scales to 500,000 end-points (not theoretically, but in practice) and the breadth of capabilities, we were more than intrigued. We were determined to do what we could to invest in David, Orion, and team.
Redefining State of the Art
In enterprises, one team is generally responsible for securing end-points, while another is responsible for managing them (systems management). Typically, each team uses its own tools, and each is independently struggling to keep pace with modern network security threats and the scale of modern networks.
Today’s IT Pros on both security and management teams know the types of information they need from their network. With current tools these questions require careful planning, significant infrastructure, and a fine balance between what IT needs to know and the cost to the end user who is working on the computers that are being queried – if you get it wrong, you can cause slow logons and sluggish performance at inconvenient times. However, to effectively manage and secure networks and provide assurance of compliance with government and industry regulations IT Pros absolutely require information such as hardware configuration, software inventory, network usage, patch and update status, and more. In addition, today’s socially engineered security risks are often combinations of seemingly simple combinations of running programs, files or attachments on the system, and a few other clues. An IT Pro walking up to a PC or Mac could easily obtain all of this information, but for all practical purposes it is impossible for them to gather that data from the thousands of end-points they are responsible for with any level of ease or timeliness.
Getting that data at scale is typically hard and slow because almost every Systems Management tool uses a classic hub (servers) and spoke (end-points) architecture. IT Pros deploy multiple servers running on network segments with high-end databases and significant networking hardware combined with fairly elaborate end-point runtimes. Even when this state of the art deployment is carefully tuned, the best case at very large scales can be 3 days to “compute” the answer to critical operational questions, assuming you knew ahead of time you were going to ask those questions. By this time the information would be out of date and by then the whole problem you were thinking about has probably changed. As a result most IT Pros know that best case the data is approximate, and worst case just worthless. For mission critical problems, such as compliance with HIPAA (healthcare) or PCI (electronic payment) regulations, this is more than just inconvenient for IT, it can cause a painful failure with board-level visibility.
The state of the art for Security is all about building stronger and taller walls between the enterprise network and the internet. We’re familiar with these approaches across the basics of firewalls, more sophisticated security appliances and adaptive architectures, and of course the typical security suites that run on end-points. Unfortunately, the bad guys are wise to that game, and modern threats are created anticipating that these protections are in place—in many cases, the bad guys actually “QA” their attacks against the systems enterprises use before they release them. In addition, today’s malware is targeted to particular organizations, and is often put in place by a series of seemingly benign or undetectable actions. Malware, a bot, or a backdoor make their way onto the network leaving behind a series of benign clues—a running process, a changed file, a memory signature, or a specific network packet. It is only taken together that a pattern emerges. It is only after the fact or with an IOC (indicator of compromise) in hand that IT Pros can potentially track down end-points that have been compromised. Unfortunately, IT is literally swamped by IOCs to investigate and there are no effective tools that support this wide range of questions and even if you could, the state of the art would give answers in days, long after the damage was done.
Even with these challenges, both of these state of the art approaches have their place in a modern network. It would be irresponsible to run a network without basic asset management or network firewalls and end-point protection such as anti-virus. Unfortunately, for the vast majority of both threats and systems management, the needs of IT Pros are far more dynamic and complex than existing systems can provide. This is the opportunity where Tanium adds unique value to the tools of the modern IT and Security professional.
At 16z, we love the opportunity to partner with enterprise companies that are either working to radically improve the way a given IT need is met with software or transforming the IT landscape by re-creating or re-defining the traditional categories with unique software. Tanium is magical because it is transformative across both of those measures.
Innovating Tanium
In practice, the Tanium team accomplished nothing short of a complete rethinking of how IT Pros manage, secure, and maintain the end-points in their network—every node on the network can now be interrogated, managed, updated, and secured, instantly from a browser. Literally, you can ask almost anything of an end-point from basics such as configuration, patch status, software inventory compliance, performance, reliability measures, telemetry, network activity, files, and more (basically anything you can ask of a running system) and get answers back in seconds. Not only can you ask questions, but you can take actions as well—distribute and install updates, shut down processes or executables, remove or quarantine files, and so on. All of this happens in seconds, across your entire network of end-points, across LAN segments and the WAN, from branch offices to headquarters to the data center.
Orion walked us through the magic of Tanium. It became clear very quickly that David, Orion and team have invented a completely new way to think about managing and securing a network of computers. The magic of Tanium is built out of four innovative technology pillars:
- Runtime. The Tanium runtime builds on the end-point management lessons of BigFix. The runtime serves as the platform for asking the end-point questions in the scripting language of your choice (VBscript, Powershell, WMI, Python, Unix Shell, and most any other language), packaging up the answers and getting them to single server/VM that coordinates the activities. The runtime also provides actions allowing you to make changes across your entire network, instantly. The end-point runtime is a couple megabytes, takes almost no CPU or RAM, and incurs nearly imperceptible network usage.
- LP2P Networking: End-points secured by Tanium do not drive up costly WAN traffic but instead communicate between end-points on the local area network. Expensive WAN load is vastly reduced because rather than all end-points trying to reach a single data center across the WAN, answers and actions are coordinated across an incredibly efficient linear peer-to-peer (LP2P) architecture—an innovative hybrid of mesh and peer-to-peer concepts designed and validated for the enterprise. LP2P is self-healing and architected for fault tolerance, transient end-points, and global WAN segments connected in a typical manner.
- Natural Language. The interface to Tanium is through a simple text box where you can use natural language to ask questions of the entire set of end-points. Just like using web search, each question gives you suggestions for follow up questions, refinements, and ways to improve your queries. You use natural language questions to generate tables, charts, time series, and other representations of your near real-time network status—instantly.
- Security. The entire Tanium platform was of course architected from the ground up to be secure enough for the largest enterprise and federal networks – Tanium affords IT Pros incredible power and flexibility in managing and securing end-points, and they recognize the need to ensure that power stays in the right hands. As a result, all traffic is FIPS level secured, actions are controlled and validated by signed certificates, and administrators have fine-grained control over the types of queries and actions permitted by different users within IT.
If you’re running existing state of the art tools for managing and securing your end-points, you have a fixed set of diagnostic questions that you routinely ask and then store the answers in a database for later analysis. Even if it’s a simple question like what version of OS software your computers are running, it will take a few days or more to get answers. If you have a crisis requiring new information, you likely push out an emergency logon script or dreaded background process to add a new question to the list of slowly collected answers, and days later you know the approximate answer.
As a result of the innovations above, Tanium completely upends the thinking about how this should work. By analogy, if you think about the current state of the art as a printed set of classic encyclopedias then Tanium is like having the entire internet at your disposal through a search engine. Rather than a set of fixed questions and answers, you use Tanium to explore your end-points. When new security threats arise you can immediately explore your risk by using any telemetry to diagnose your risk and then using any mechanism to take corrective actions—instantly.
A top of mind example for all of us is the outbreak of Heartbleed. As soon as your operations center received notice of this vulnerability, there was one simple question “what variants and versions of OpenSSL are we running across all servers and VMs”. Almost no management and inventory system would have this readily available. Many would have first relied on what was believed to the “standard” images, but later would find out that isn’t enough. With Tanium, you just ask a question in natural language and within seconds you can have any level of details required on the servers and VMs running OpenSSL. You can then shut those servers down, deploy updates, or monitor actions—instantly.
Identifying and securing end-points for compliance with regulations, software licensing, or corporate policy is equally simple. When talking to Orion about Tanium, I searched my own experience for what I thought was a trick question. I wanted to know “how many end-points had attached USB memory stick and written to it recently” (a potential information leak, compliance issue, or malware vector all in one simple and common operation). Once again Tanium’s magic delivered an answer from a natural language query in just a few seconds for thousands of computers.
In addition to all of this, Tanium is also a true platform. IT Pros can utilize mature REST, SOAP, and syslog APIs to connect the results of Tanium queries to their favorite big data destination and develop time series models of their end-points, and mine the data for patterns. Because the Tanium runtime has such a minimal impact it is possible to collect thousands of independent data points continuously from hundreds of thousands of end-points, feeding the predictive analytics and big data systems that enterprises are building today with extremely valuable data. This type of analysis allows for finding points in time when the network changed, identifying malware, bots, and other exploits that we all know escape traditional firewalls and anti-virus. Using the platform, IT can also create tailored dashboards and custom actions that enable monitoring and guarantee compliance of end-points with standards.
Tanium and a16z
I could go on and on about the magic of Tanium that David, Orion, and the amazing team created. In fact when we talk about Tanium we describe it as an entrepreneur trifecta. First, David and Orion are experienced and successful entrepreneurs. Second, Tanium is a product that builds on innovative and inventive technology that could only come about from a team with years of experience and a depth of understanding of the enterprise. And third, Tanium is already a successful and profitable company with dozens of customers in massive, mission-critical and global deployments.
With this incredible story, Andreessen Horowitz could not be more excited to be leading an investment in Tanium. I’m personally super excited to be joining the Tanium Board where I will work closely with David, Orion, and the team.
–Steven Sinofsky (@stevesi, steven@a16z.com)
This post is also on a16z.
If at first you don’t succeed: disrupting incumbents in the enterprise
 I was talking with a founder/CEO of an enterprise startup about what it is like to disrupt a sizable incumbent. In the case we were talking about the disrupting technology was losing traction and the incumbent was regaining control of the situation, back off their heels, and generally felt like they had fended off the “attack” on a core business. This causes a lot of consternation at the disrupting startup as deals aren’t won, reviews and analyst reports swing the wrong way, and folks start to question the direction. If there really is a product/market fit, then hold on and persevere because almost always the disruption is still going to happen. Let’s look at why.
I was talking with a founder/CEO of an enterprise startup about what it is like to disrupt a sizable incumbent. In the case we were talking about the disrupting technology was losing traction and the incumbent was regaining control of the situation, back off their heels, and generally felt like they had fended off the “attack” on a core business. This causes a lot of consternation at the disrupting startup as deals aren’t won, reviews and analyst reports swing the wrong way, and folks start to question the direction. If there really is a product/market fit, then hold on and persevere because almost always the disruption is still going to happen. Let’s look at why.
Incumbent Reacting
The most important thing to realize about a large successful company reacting to a disruptive market entry is that every element of the company just wants to return to “normal” as quickly as possible. It is that simple.
Every action about being disrupted is dictated by a desire to avoid changing things and to maintain the status quo.
If the disruption is a product feature, the motion is figuring out how to tell customers the feature isn’t that important (best case) or how to quickly add something along the lines of the feature and move on (worst case). If the disruption is a pricing change then every effort is about how to “manage customers” without actually changing the price. If the disruption is a new and seemingly important adjacent product, then the actions focus on how to point out that such a product isn’t really necessary. Across the spectrum of potential activities, it is why the early competitive responses are often dismissive or outwardly ignore the challenger. Aside from the normal desire to avoid validating a new market entry by commenting, it takes a lot of time for a large enterprise to go through the work to formulate a response and gain consensus. Therefore an articulate way of changing very little has a lot of appeal.
Status quo is the ultimate goal of the incumbent.
Once a disruptive product gains enough traction that a more robust response is required, the course of action is almost always one that is designed to reduce changes to plans, minimize effort overall, and to do just enough to “tie”. Why is that? Because in a big company “versus” a small company, enterprise customers tend to see “a tie as a win to the incumbent”. Customers have similar views about having their infrastructure disrupted and wish to minimize change, so goals are aligned. The idea of being able to check off that a given scenario is handled by what you already own makes things much easier.
Keep in mind that in any organization, large or small, everyone is at or beyond capacity. There’s no bench, no free cycles. So any change in immediate work necessarily means something isn’t going to get done. In a large organization these challenges are multiplied by scale. People worry about their performance reviews; managers worry about the commitments to other groups; sales people worry about quarterly quotas. All of these worries are extremely difficult to mitigate because they cross layers of managers and functions.
As much as a large team or leader would like to “focus” or “wave a wand” to get folks to see the importance of a crisis, the reality of doing so is itself a massive change effort that takes a lot of time.
This means that the actions taken often follow a known pattern:
- Campaign. The first thing that takes place is a campaign of words and positioning. The checklist of features, the benefits of the existing product, the breadth of features of the incumbent compared to the new product, and so on. If the new product is cheaper, then the focus turns to value. Almost always the campaign emphasizes the depth, breadth, reliability, and comfort of the incumbent’s offer. A campaign might also be quite negative and focus on a fear, compatibility with existing infrastructure, or conventional wisdom weakness of a disruptor, or the might introduce a pretty big leap of repositioning of the incumbent product. A good example of this is how on-premises server products have competed with SaaS by highlighting the lack of flexibility or potential security issues around the cloud. This approach is quick to wind up and easy to wind down. Once it starts to work you roll it out all over the world and execute. Once the deals are won back then the small tiger team that created the campaign goes back to articulating the product as originally intended, aka normal.
- Partnership. Quite often there can be a competitive response of best practices or a third-party tool/add-on that appears to provide some similar functionality. The basic idea is to use someone else to offer the benefit articulated by a disruptive product. Early in the SaaS competition, the on-premises companies were somewhat quick to partner with “hosting” companies who would simply build out a dedicated rack of servers and run the traditional software “as a service”. This repotting plants approach to SaaS has the benefit that once the immediate crisis is mitigated, either the need to actually offer and support the partnership ends or the company just becomes committed to this new sales channel for existing products. Again, everything else continues as it was.
- Special effort. Every once in a while the pressure is so great internally to compete that the engineering team signs up for a “one off” product change or special feature. Because the engineering team was already booked, a special effort is often something carefully negotiated and minimized in scope and effort. Engineering minimizes it internally to avoid messing up dependencies and other features. Sales will be specific in what they expect the result to do because while the commitment is being made they will likely begin to articulate this to red-hot customer situations. At the extreme, it is not uncommon for the engineering team to suggest to the sales organization that a consultant or third-party can use some form of extensibility in the product to implement something that looks like the missing work. The implications of doing enterprise work in a way that minimizes impact is that, well, the impact is minimized. Without the proper architecture or an implementation at the right level in the stack, the effort ultimately looks incomplete or like a one-off. Almost all the on-premise products attempting to morph into cloud products exhibit this in the form of features that used to be there simply not being available in the “SaaS version”. With enough wins, it is almost likely that the special effort feature doesn’t ever get used. Again, the customer is just as likely to be happy with the status quo.
All of these typical responses have the attribute that they can be ignored by the vast majority of resources on a business. Almost no one has to change what they are doing while the business is responding to a disruptive force. Large incumbents love when they can fend off competitors with minimal change.
Large incumbents love when they can fend off competitors with minimal change.
Once the initial wave of competitive wins settles in and the disruptive products lose, there is much rejoicing. The teams just get back to what they were doing and declare victory. Since most of the team didn’t change anything, folks just assume that this was just another competitor with inferior products, technology, approaches that their superior product fended off. Existing customers are happy. All is good.
Or is it?
Disruptor Persevering
This is exactly where the biggest opportunity exists for a disruptive market entry. The level of complacency that settles into an incumbent after the first round of victories is astounding. There’s essentially a reinforcing feedback loop because there was little or no dip in revenue (in fact if revenue was growing before then it still is), product usage is still there, customers go back to asking for features the same as they were before, sales people are making quota, and so on. Things went back to normal for the incumbent.
In fact, just about every disruption happens this way–the first round or first approaches don’t quite take hold.
Why is this?
- Product readiness can improve. Obviously the most common is that the disruptive product simply isn’t ready. The feature set, scale, enterprise controls, or other attributes are deficient. A well-run new product will have done extensive early customer work knowing what is missing and will balance launching with these deficiencies and with the ability to continue to develop the product. In a startup environment, a single company rarely gets a second shot with customers so calibrating readiness is critical. Relative to the broader category of disruption, the harsh reality is that if the disruptor’s idea or approach is the right one but the entry into the market was premature, the learning will apply to the next entry. That’s why the opportunity for disruption is still there. It is why time to market is not always the advantage and being able to apply learning from failures (your own or another entry) can be so valuable.
- Missing ingredient gets added. Often a disruptive product makes a forward-looking bet on some level of enterprise infrastructure or capability as a requirement for the new product to take hold. The incumbent latches on to this missing ingredient and uses it to create an overall state of lack of readiness. If there’s one thing that disruptors know, it is not to bet against Moore’s law. If your product takes more compute, more storage, or more bandwidth, these are most definitely short-term issues. Obviously there’s no room for sloppy work, but by and large time is on your side. So much of the disruption around mobile computing was slowed down by the enterprise issues around managing budgets and allocation of “mobile phones”. Companies did not see it as likely that even better phones would become essential for life outside of work and overwhelm the managed phone process. Similarly, the lack of high-speed mobile networks was seen as a barrier, but all the while the telcos are spending billions to build them out.
- Conventional wisdom will change. One of the most fragile elements of change are the mindsets of those that need to change. This is even more true in enterprise computing. In a world where the average tenure of a CIO is constantly under pressure, where budgets are always viewed with skepticism, and where the immediate needs far exceed resources and time, making the wrong choice can be very costly. Thus the conventional wisdom plays an important part in the timeline for a disruption taking hold. From the PC to the GUI to client/server, to the web, to the cloud, to acceptance of open source each of these went through a period where conventional wisdom was that these were inappropriate for the enterprise. Then one day we all wake up to a world where the approach is required for the enterprise. The new products that are forward-looking and weather the negatives wishing to maintain the status quo get richly rewarded when the conventional wisdom changes.
- Legacy products can’t change. Ultimately the best reason to persevere is because the technology products you’re disrupting simply aren’t going to be suited to the new world (new approach, new scenarios, new technologies). When you re-imagine how something should be, you have an inherent advantage. The very foundation of technology disruption continues to point out that incumbents with the most to lose have the biggest challenges leading through generational changes. Many say the enterprise software world, broadly speaking, is testing these challenges today.
All of these are why disruption has the characteristic of seeming to take a much longer time to take hold than expected, but when it does take hold it happens very rapidly. One day a product is ready for primetime. One day a missing ingredient is ubiquitous. One day conventional wisdom just changes. And legacy products really struggle to change enough (sometimes in business or sometimes in technology) to be “all in” players in the new world.
Of course all this hinges on an idea plus execution of a disruptive idea. All the academic theory and role-playing in the world cannot offer wisdom on knowing if you’re on to something. That’s where the team and entrepreneur’s intuition, perseverance, and adaptability to new data are the most valuable assets.
The opportunity and ability to disrupt the enterprise takes patience and more often than not several attempts, by one or more players learning and adjusting the overall approach. The intrinsic strengths of the incumbent means that new products can usually be defended against for a short time. At the same time the organization and operation of a large and successful company also means that there is near certainty that a subsequent wave of disruption will be stronger, better, and more likely to take hold simply because of the desire for the incumbent to get back to “normal”.
–Steven Sinofsky (@stevesi)


