Posts Tagged ‘privacy’
Privacy and Security: Less Rhetoric and More Product
 Tim Cook’s recent remarks on privacy described as “blistering” or an “epic subtweet” amplified a discussion about the web and privacy. Given the polarizing framing of this topic, collectively as an industry (and beyond) we have been less than stellar at discussing these topics. We’ve also done a poor job at proposing broad initiatives to address concerns raised in the discussion.
Tim Cook’s recent remarks on privacy described as “blistering” or an “epic subtweet” amplified a discussion about the web and privacy. Given the polarizing framing of this topic, collectively as an industry (and beyond) we have been less than stellar at discussing these topics. We’ve also done a poor job at proposing broad initiatives to address concerns raised in the discussion.
We seem to be caught in that difficult situation of having defined the problem as requiring an all-or-nothing solution, which is never a good place to be because the reality is more nuanced. Dustin Curtis points out the nuance in this post Privacy vs. User Experience.
Rather than debate extremes that are neither desirable nor technically possible, I want to suggest there are technical problems that can and should be solved, and doing so would make the Internet a better place for people using Internet services and businesses providing services.
“Get Over It”
Way back before there were mobile phones, today’s search engines or social networks, or cloud computing, Sun Computer founder Scott McNealy said, “You have zero privacy anyway. Get over it.” Yikes!
The statement at the time had elements of truth, fear, and absurdity. It was pre-bubble, heck it was the 1990’s still and 1984 was still fresh on our collective psyche. The statement did however foretell a significant change in what was going to happen.
Such a debate is not new. While the scale is different, I recall three major products from reputable companies that introduced me to the absolutes and polarization of the privacy “debate”.
Robert Bork was nominated for the Supreme Court of the US in 1987 (and later failed confirmation in the Senate). One of the moments of the very contentious confirmation was the appearance of the nominee’s personal records from a video rental store (delivered to the press as a hand-written list). This was clearly a dubious act later codified to be illegal. I think for my generation, it was the first experience of how things would change in the digital age of record keeping via computer. At the time there were quite a few connections made to how the FBI maintained files on people, but this was the first time the “incriminating” information came from a benign consumer business.
Lotus Marketplace was a product developed in the late 1980s. It had the gall to collect data sources like US Census data and public phone number listings and put it on CD ROMs for marketing people to use with Lotus 1-2-3 to plan and analyze marketing campaigns. Even worse it had household and zip code level data about the US (all based on sources already in existence and available to businesses. Much debate centered on how one could take this data and potentially “triangulate” it to actually learn something about an individuals. Likely due to the massive outcry, the product was never released to the market. From this early experience we can see the combination of an existing data source and distribution of digital data changes the dynamic of privacy.
Credit card companies became famous for the offers inside your monthly statement in the 1980s—little paper inserts with offers to buy custom return address labels, go on cruises, or secure other financial products. Like confetti they would fall out of the envelope. These were the very definition of “junk mail”. Then the companies began to use your previous purchase history to target these inserts. If you were paying attention then you realized that junk mail started to look less and less junky. This “feature” turned into a fear that credit cards were selling your charging history to random companies. Of course that was not true (in fact such information was closely guarded). The way they worked was the credit card company would offer inserts matching specific target customers and insert them for a fee. Because financial companies were already tightly regulated, the path to today’s Byzantine opt-in/opt-out direct mail policies can be traced to this history.
Fast-forward to today and we know that the services we use amass significant information about how we interact with them. The medical establishment has my medical history available to a constellation of caregivers (and to me) that make delivery of quality care easier and faster. Credit card companies know my charging history and patterns and can alert me to fraud instantly (even if too often incorrectly). Netflix knows all the movies I watch (and even how much of them) and uses that to improve a highly valued recommendation engine. Pizza delivery services know what we order and can save time and effort by using that history (and also offer promotions based on that). Google Maps knows where I travel and when and proactively offers suggestions on when I should depart depending on current traffic. The examples are endless. In fact the benefits of maintaining my history of interaction with a service are immense and a deciding factor in which services I choose to use.
The risk that we have assumed on an individual service is that providers cannot maintain the integrity of their own services. This is a network technology risk as we have seen with Target or Home Depot. It is a human risk as we have seen with breaches like Sony where people set out to arbitrarily harm others. It is a national security risk such as we have seen with the recent attack on the federal government in the US, allegedly orchestrated by a nation-state.
The risk that a company will do “bad” things with the data it has as a result of using a service by all appearances is infinitesimal. Will some features feel creepy to some? Of course that is the case. Some people don’t like having their name and order remembered by the barista (a human form of big data).
The risk that a company will be breached and the data put to uses not intended by the company is not only there, but it is significant. This is a technology problem our industry needs to solve. One thing is clear and it is that the biggest companies are the biggest targets and the largest technology companies are (I would assert) the most savvy and adept at these issues. But the problem is incredibly difficult in a world of nation-states leading some attacks.
I am not a “get over it” person, but rather an engineer and product person that sees the desire of companies to use data to deliver far better services and that desire is leading to immense innovation in how commerce is conducted and the internet is used. At the same time this data is very attractive to bad actors for a variety of reasons and that is a technical challenge our industry will rise to as it has time and time again. This is first and foremost a security problem due to bad actors. The privacy challenges come from what happens with the data when used by good actors in the system and this is a much more nuanced challenge.
I do believe that if you simply want to skip using services that compile data then you should be able to opt-out of services or to simply choose to use alternative services, but there is no obligation for any given service to provide the non-personalized, non-targeted, non-historic version of a service. The market for such services is likely to shrink and that might be unfortunate. The free market is like that. Sometimes something highly valued at a point in time becomes non-economic or scarce as companies compete for a larger market. I don’t have an easy answer for customers that want to use the internet without a trail—I strongly strongly support the services and technologies that allow for that (encryption, tor, etc.). I think the evidence is that this is not where most people will go. Historically, if there is money to be made then businesses will be created to seek that opportunity.
But What About Web Privacy
Why all the kerfuffle over privacy, again? My view is that this is rooted in the experience of the web that is just getting worse and many are frustrated. Security breaches of private information compound this concern and are symbolic of technology challenges on the Internet. Security breaches are unrelated to privacy in the sense that breached systems are not ad-funded user profiles, but wholly orthogonal and essential line of business information. The challenge is that our collective experience on the web is the result of a mountain of technologies built out over the past 20 years in an effort to deliver services to consumers that are paid for by advertising.
The act of delivering services paid for by advertising is not only inherently good and beneficial, but also essential to the amazing spread and growth of internet services. It should be readily apparent that the rise of internet advertising supported services is singularly responsible for the mass scale growth of billion-customer services. That is only good.
It isn’t that all my data is in the cloud waiting to be mined—AT&T, Comcast, Blockbuster, American Express, Nordstrom, Safeway, Amazon, UPS, and more already had a crazy amount of information about me and I would love exactly none of that to be in the hands of a bad actor. Even Apple knows every song I ever bought (if this happens to leak, I am saying now that I bought Barry Manilow Live for a friend’s birthday party), every place I ever used Maps to visit, and all my mail and contacts. Google has much of this too. I know Google is not selling my name and that information to anyone, but like a credit card insert they will match an advertisement for services to “people who visit New York”.
The challenge is that in an effort to improve the revenue yield of services all too often technology solutions available were used, abused, or otherwise misused in ways that degraded the overall experience of the internet for too many. The problem is that web ads are awful experiences and getting worse. We need technical solutions to this 20-year pile of legacy features.
My view is that the horrible experience of browsing the web and seeing those ads that “interfere” with using the web, and fear that this experience will become what we all experience on the pristine world of mobile is at least partially and likely largely responsible for using privacy as the anchor of this debate. In Steve Jobs’ “Thoughts on Flash” he was completely accurate about the problems of the runtime. That runtime was used as the basis of ads. He may or may not have been against ads, but many people were quite frustrated by the technical execution of ads in Flash and so his appeal resonated. It is just few of us could do much about it.
The industry did not stand still. Over the years we have seen browsers add pop-up blocking. While advertisers were angry, people cheered. We’ve seen a dramatic rise in ad-blockers. Yet we still see a constant stream of complaints on the web about “wait 5 seconds to see your story” or user experiences that test even the most savvy gamer when it comes to finding and clicking the close box. But this is the technology choice on the web, not the nature of advertising itself.
Fixing the Web
I was a strong supporter of evolving the browser to support features that allowed consumers to choose how to secure their experience. From popup blockers to Do Not Track I advocated for this type of control. The reason was not because I am against “free” services or want everyone to browser anonymously without footprints. The reason is because the web got so messy that the recourse seemed to be to help people as individuals.
On a personal note, championing features like Do Not Track (DNT) was one of the more educational chapters in my own career. I had never experienced the “slippery slope” defense quite like that—the idea that a feature was just an on-ramp to the apocalypse would not overstate the reaction to such a feature. The argument against DNT was that overnight the free internet would vaporize, which was also the argument against popup blockers or the removal of Flash.
There are three parts of today’s web that are technology problems waiting for solutions. The solutions are either difficult or undesirable but I believe solving them would go a long way towards framing the debate as a choice between “selling your personal information” or “there will be no services on the Internet”.
¶ Ads are awful. First and foremost, today’s ad formats are relatively hostile to consumers using services. We all know that ads want to be noticed. That’s a given. The openness and programmability of HTML5 and browsers created an open season on the technology used in ads and while there is plenty of innovation there are more negatives. Even the biggest and most popular sites can grind a browser to a halt on a powerful desktop PC. With television, for years advertisers tried tricks like raising the volume of an ad in order to get you to notice. This was fixed in the US by government regulation in 2012 with the CALM Act. We need such a movement for the internet. I believe the presence of advertising networks and internet standards bodies already in place (that create standard ad formats) could easily create standards around fly overs, popups, tiny close boxes, interstitial timings, audio and video playback, and so much more. We of course don’t want to stifle innovation, shut off A/B testing, or otherwise become the government but certainly we can create better technology and designs for advertisement. The popularity of browser based ad blockers is not about “privacy” but just about a desire to read more stuff and use more services in some reasonable way, I would assert.
¶ Content responsibility is lacking. One of the biggest places where advertising meets real-world security concerns is when advertisements themselves are vectors for security exploits. The advertising networks of today are well-known repositories for the distribution of zero-day exploits and malware insertion. While one could fault the browsers for not being able to secure against this, one must also fault the ad networks for allowing this content in the front door. One can also fault the sites that host this. As a consumer visiting a site, neither the site nor the ad network act responsibly relative to this type of content. All will do takedowns but the effort to own up to this challenge is not what I think it could be (there’s plenty of hard work, but not enough). Ad formats themselves are part of the challenge. Should ads be allowed the full power of the browser and runtimes? Should we define a maximal set of capabilities that ads can use? There is lots to be done here.
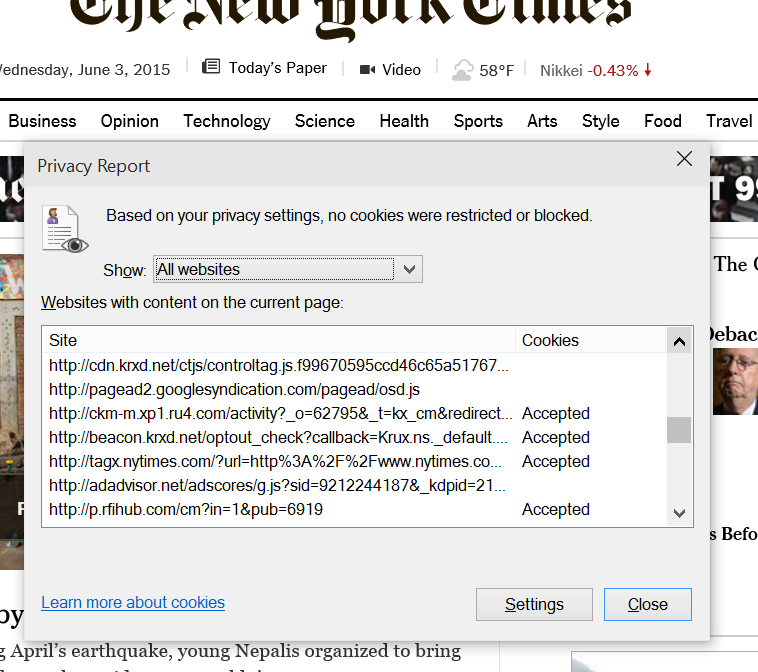
¶ Accountability is non-existent. While we were working on “Do Not Track” one of the things that surprised me the most was the lack of accountability for some core information about people that I believe is a privacy challenge. Some have talked about this as the problem with cookies (again a polarizing way to describe something since I also like not having to sign into services I use all the time on my home PC again and again). But mostly this is probably the most unsavory part of the web when it comes to this issue of privacy and security. Quite simply, once I start using a site, especially if I am logged in, then the ability for that site to see and store my internet traversal history is just too easy. The accountability for this is nowhere to be seen. Even the most trustworthy of sites are in need of improvement along these lines. When I visit nytimes.com (just an example of an incredibly reputable site) I am visiting dozens and dozens of other web sites just on the home page. Below you can see a portion of the Web Page Privacy view from Internet Explorer showing all the URLs that compose a page. This is quite a surprise to most people who think that the links might go to a few photos or to some other servers for code or features. These are not subdomains of nytimes.com but whole other sites (honestly, do I really trust the domain ru4.com, which by the way resolves to “Perfect Privacy Incorporated” but has no home page or corporate information page). What are the privacy policies of these sites? What information do they get? Do they combine this information across their customers? It isn’t that they do this, it is that as a consumer I have no knowledge and as a site I visit the Times offers no transparency. This to me feels like a big challenge. I don’t mind the Times having my browsing history for the Times, not at all especially if I am logged on. I do mind all these companies with mysterious URLs following me around. When a company has my transaction history and uses it to deliver services it does not send that history to others, it has others send information to them to use the history. Why can’t sites implement ads and analytics in this manner? You can see the lack of accountability in the terms of service, as shown for the nytimes.com site below.

Solutions are on the way
I believe there are deep concerns that the mobile internet will devolve into the desktop internet and we will lose the clean slate we currently have. This would be a shame because we need ad-supported services on mobile as well. We know the current experience of using a browser on mobile is racing towards the desktop—ironically because the browsers are getting better with video, script and runtime support and more.
The recent announcements by Facebook and partners show how innovation can happen. By providing a mechanism for ad-supported content to appear within a Facebook app experience natively and in a format that does not (necessarily) support many of the bad practices of the desktop web my view is that advertising can be more natural and at the same time relevant. My hope is that the runtime and/or the policies do not support the arbitrary nature of the desktop web and the experience does improve dramatically and stay that way for a while.
While all of this is taking place in the consumer world, the business computing landscape is being altered by the encroachment of consumer services. The natural reaction of the enterprise is to disable or turn off this access, which many believe is a losing strategy. In this context the biggest concern I would bring is the notion that the business internet will live along side the consumer internet and all will be good. As a consumer when I use my mobile device for work and personal, I want that conflation to exist in the service data I use. If I buy books for my own personal interest but use them for work or even get reimbursed by work, then I want my Amazon profile to have that. If I use Maps to navigate to partners or customers I don’t wan to sign on and sign off or use a different Maps instance, but want to train a single instance. If I use a productivity tool for home and work, I want the usage and quality data to flow to the service so that the product gets better for how I use it. In all cases, the unified view of “me” makes everything I use better and that makes me a better employee using tools. I’d hate for IT to see privacy as another thing to enforce by degrading my experience.
¶ Ultimately, the web will continue to evolve and free services will continue to grow. That is super important to the future for the next 3 billion internet users. There will always be a distribution of views of how much information should be saved and what services will be valued. We should no judge each other on that any more than we can expect every service to cater to ever perspective on this topic. For a moment, we can look at the challenges we’re discussing and see the engineering and product development work that can be done. I believe we can collectively improve the current situation if we take steps to design new products and services that meet the needs of all parties.
# # # # #



{kind=link}