
I drove by the fork in the road and went straight.
— Jay-Z (see author’s endnote)
One of the most vexing product challenges is evolving the UX (user experience, and/or user UI) over long periods of time, particular when advancing a successful product with a supportive and passionate community.
If you are early and still traveling the idea maze in search of product-market fit, then most change is good change. Even in the early days of traction, most all changes are positive because they address obvious shortcomings.
Once your product is woven into the fabric of the lives of people (aka customers) then change becomes extraordinarily difficult. Actually that is probably an understatement as change might even become impossible, at least in the eyes of your very best customers.
The arguments are well-worn and well-known. “people don’t like change”…”muscle memory”…”takes more time”…”doesn’t take into account how I use the product”…”these changes are bad”…”makes it harder to doX”…”breaks the fundamental law of Y”…”what about advanced users”…”what about new users”…and so on. If you’re lucky, then the debate stays civil. But the bigger the product and the more ardent the “best” (or most vocal?) customers, well then the more things tilt to the personal and/or emotional.
Just this past week, our feeds were filled with Twitter rumored to make a big change (or even changing from Favorite to Like), Uber changing a logo, and even Apple failing to change enough. It turns out that every UI/UX change is fiercely monitored and debated. All too often this is a stressful and unpleasant experience for product designers and an extremely frustrating experience for the customers closest to the product. Even when changes are incredibly well received, often the initial response is extremely challenging.
For all of the debates, a product that fails to dramatically change is one that will certainly be bypassed by the relentless change in how technology is used.
Yet change, even of a core user experience, is an essential part of the evolution of a product. For all of the debates, a product that fails to dramatically change is one that will certainly be bypassed by the relentless change in how technology is used. We do not often consider the reality that most new products (and services) we enjoy are often quite similar to previously successful products, but with a new user experience.
Consider that the graphical interface for spreadsheets and word processors replaced whole companies built around predominantly similar capabilities in character mode interfaces. The competitive landscape for browsers was framed by having minimal interface. Today’s SaaS tools often lead with capabilities similar to legacy products expressed through consumerized experienced and cloud architecture.
Technology platform disruptions are just that, disruptive, and there’s no reason to think that the user experience should be able to smooth out a transition. There’s every reason to think that trying to make a UX transition go smoothly might be a counter-productive or even a losing strategy.
The biggest risk in product design is assuming a static world view where your winning product will continue to win with the same experience improving along the same path that got you success in the first place.
The reality is that if you are not doing more in your product you are doing less, and doing more will eventually require a redesign and rethinking over time. The corollary is that if you are only doing what you’ve always done, but a little better every time, then as a practical matter you are also doing less relative to always-emerging competitive alternatives.
The biggest risk in product design is assuming a static world view where your winning product will continue to win with the same experience improving incrementally along the same path that got you success in the first place.
There are dozens of amazing books that tell you how to design a great user experience. There are seemingly endless books and posts that are critical of existing user experiences. There are countless mock-ups that say how to do a better job at a redesign or how to fix something that is in beta or already changed (see The Homer). Few and far between, however, are the resources (or people) that guide you through a major change to user experience.
No one tells you that you’ll likely face your most difficult product design choices when your product is incredibly successful but facing existential competitive challenges — competitive challenges that your most engaged customers won’t even care about.
This essay is is presented in the following sections:
- User Experience Is Empowerment
- Everyone’s A Critic
- Pressure To Change
- 5 Ways To Prepare
- 5 Approaches To Avoid
- Reality
User Experience Is Empowerment
At the most basic human level, the mastery of a tool (a user interface or experience) is about empowerment. Being able to command and control a tool feeds a need many of us share to be in control of our environment and work.
Historically we (all) seek to be the master of our “life tools” whether an shovel, a horse, a car, a PC, or the arcane commands of a modern social network. Something magical happens for a product (and company) when it is so compelling that people spend the time and effort required to master it.At that moment, your product becomes an essential part of the lives of customers, customers who come to believe their world view is shared by “everyone”.
Those customers become your very best customers who see your tool as a path to mastering some of the ever more complex aspects of life or work.Those same people also become your harshest critics when you try to change, anything.
A Story
Permit me to share an example of how this empowerment can work, deliberately using an historic example few will remember.
Some time in the mid 1990’s I was a product (program in Microsoft lingo) manager on Office and we were trying to figure out how to transition from a consumer app (yes we used the phrase consumer app back then) to an enterprise platform (that word was new to us). There were many elements to this, but one in particular was the setup and deployment of the Office apps.
As is often the case, customers were ahead of us on the product team when it came to figuring out the most efficient way to copy the Office bits (all 50MB of them) from floppies to a file server to desktops and laptops. Customers had all sorts of things they wanted to do when “installing” Office onto a PC — changing default settings, removing unneeded files like clipart, and even choosing which drive to use for the bits. Many of those could be controlled by the setup program that was itself an app requiring human interaction, save for a few select capabilities. PC admins wanted to automate this process.
As you might imagine, admins cleverly reverse-engineered the setup script file that was used to drive the process. This was a file that did for the comma what LISP did for parentheses. It was a giant text file filled with record after record of setup information and actions, with an absurd number of columns delineated by commas. In fact, and this is a little known embarrassment, the file was so unwieldy that to edit it required a non-Microsoft editor that could handle both the text file length and the line width. Crazy as that was, a very large number of PC admins became experts in how to “deploy” Office by tweaking this SETUP.INF. I should mention, one missing comma or unmatched quote and the whole system went haywire since it was never designed to be used by anyone but the half dozen people at Microsoft who understood the system and were backed by a large number of test engineers.
We believed we had a clever idea to solve a broad range of customization, security, and even engineering challenges which was to replace the fragile text file and third party text editor with a robust database and graphical interface. Admins could then push a customized installation to a PC without being in front of it and the PC could even repair an installation if it somehow got corrupted or munged. We really put a lot of effort into solving this with a modern, thoughtful, and enterprise friendly approach. Consumers would see almost no changes.
Then came the first beta test and what could best be described as a complete disaster. Of course the customers in the beta were precisely the small same set of customers that had figured out how to hack the previous system. We had little understanding that these customers had become heroes within world of PC Admins because they could get a new PC up and running with Office in no time flat. Many had become the “goto person” for Office deployment in an era when that was a big deal. Deploying Office had become a profession.
That should have been success for us on the Office team except we changed the product so much that everything special the admins had mastered had become irrelevant. They had lost their sense of mastery over their environment.
Looked at through another lens, implicit in the change is a devaluation of the acquired knowledge and expertise of these customers.
The pain was felt by our team as well. Our goal was to make things better for admins by replacing the tedious and error prone work with a platform and slick new tools. As an added bonus the new platform greatly improved robustness and reliability and added whole new features such as install on demand. All the admins saw, however, was a big change and subsequent loss of empowerment. Looked at through another lens, implicit in the change is a devaluation of the acquired knowledge and expertise of these customers.
It would have been easy to see how to take their very specific and actionable feedback and roll the changes back to what we had before, or to introduce some bridge technology (or other “solution” discussed below). On the other hand, the competitive forces that drove these choices including web-based and browser-based tools were increasingly real. The technology shift was underway. It was clear if we did not change the product and disrupt the established processes we would have only hastened a potential disruption of our business. The market was clear about the failures of the architecture we had in place.
Everyone’s A Critic
If you ever want to go for a record on the world’s longest comment thread then author a post on user interface suggesting how a product should be improved, fixed, re-done, or just rescued. On the internet, no one knows you’re a dog but everyone is a user interface critic and/or designer. Certainly well-intentioned, each person is genuinely responding to challenges they have with a product. Some of debates over the past few months in Windows circles over the hamburger menu or the discussions around iOS’ 3D touch show the many sides to how this plays out from friends and fans alike. As I type this, Twitter even has a trending hashtag on rumored changes to the product.
Some of my favorite posts have always been the ones where someone takes the time and effort to do a rendering to improve upon an experience I worked on/managed — “this is what it should look like”. The internet and tools make it easy to turn a complex and dynamic system design into a debate about static pixels and an image or two (or twenty). The ensuing debate might be narrowly focused on specific affordances such as “the hamburger menu” or whole themes such as “skeuomorphic versus flat” design.
The presence of renderings or “design alternatives” only add stress and uncertainty to what is already an emotionally charged and highly uncertain process while at the same time creating a sense of authority or even viability. The larger the project the more such uncertainty brings trouble to the design, especially as people pile on saying “why not do that?”. It is worth noting that the internet can also be right in this regard, such as this post on iOS keyboards.
The irony is that you’re far more likely to participate in a UX discussion/debate with people with very different starting and end points than those for whom your design is intended.
There’s quite a challenge in the tech dialogs around UX. First, those that participate in the dialog are on the whole representative of power users and technology elite. More often than not, UX design is seeking to include a broader audience with a wide range of skills or even interest in using more depth functionality.
Second, the techies (to use @waltmossberg’s favorite phrase) often prefer innovations that enable shortcuts or options to existing features they see flaws with rather than doing whole new things. Techies tend to want to fix the shortcomings in what they see, which is also not always aligned with solving either broader usage challenges or even business problems. The irony is that you’re far more likely to participate in a UX discussion/debate with people with very different starting and end points than those for whom your design is intended.
While every person can be a critic (often even for products that they do not routinely use), it is also the case that every UI can become old or at least static and open to criticism. Interfaces age both internally (the team) and externally (the market). Internally, you might hit a wall on where to evolve. Customers fall into routines and usage patterns. Nothing new you do is recognized or used.
Externally, your shiny new experience that replaces some old experience (for doing slightly different or totally unrelated things) will eventually become the type of experience that gets replaced. While some think of this in terms of stylistic trends like transparency or gradients, the truth is there are functional aspects to aging as well such as interacting with touch or gestures, bundling of different feature sets, or macro trends in visual design.
When you put together the large number of critics and the certainty of your experience aging, you’re in for a challenging time to evolve your interface. Whether you have a consumer app or site with a billion users, a commerce site, a productivity tool, or a line of business app the challenges are all the same. While the scale or direct economic impact might differ, to those designers and product managers working the problem the challenges and decisions are the same, and to their customers the frustration is just as real.
Pressure To Change
Changing a user experience should in theory be no more or less difficult than a major re-plumbing or even creating the first experience. Some things make changes more difficult, or perhaps at least more open to direct criticism. With a backend change, the most visible changes might be performance or uptime (to be fair, the debates about change within product engineering are just as contested). With UX changes (additions, subtractions, reworking) everyone seems them through a more complex lens.
Changing something that people have an emotional connection to is difficult. An emotional connection creates expectations or even norms, and the natural human reaction is to defend the status quo and maintain control. The discussions of change rapidly deteriorate to preference, taste, or argument by analogy, or assertion all of which are very difficult to counter when compared to facts, stopwatches, or physics.
In my experience there are several key pressure points that drive change, beyond the most obvious of fixing what is broken. You can accept or reject these and advocate for change yourself or leave room for your competitors to capture the leadership and change. Depending on context wisdom could be found from many perspectives.
Pressure to change confronts a successful and engaging product because of:
- Evolving use cases
- Locating new capabilities
- Discovering features
- Increasing tolerance of complexity
- Isolating change leads to complex analysis of benefits
- Competing products and/or changing expectations
Evolving use cases. You might design your product to solve a specific key scenario, but over time you find a different set of use cases coming to dominate. This in turn might require rethinking the flow through the product or the features that are surfaced. In a sense this can be seen as evolving the product to meet real world usage versus theoretical usage, except it will still be a change. We see this in the amount of UX real estate legacy tools devote to print-based formatting or layout design compared to the next generation of tools that surface collaboration and communication features as primary use cases. The changes in Facebook and Facebook Messenger demonstrate this driver. A relatively minor scenario saw increased usage and strategic value driving a significant, and hotly debated, experience change.
Locating new capabilities. As new capabilities are added, most all of the time those features require some UX affordance. Almost never is there room in the existing product for the new feature. In evolving Office, we reached a point where we literally ran out of room on menus and then on toolbars (originally the goal of toolbars was to be a shortcut for things on the menus or dialog boxes, but soon features on toolbars had no counterparts in menus and dialog boxes). This challenge is even more acute in today’s mobile apps that are often “filled” from the very first release. This design challenge can be likened to trying to add a new major appliance to an existing kitchen — there is almost never room to add one until the next major redesign when flows are reconsidered. As a result, when it comes time to add UX for entirely new scenarios your product will change significantly. Recently, LinkedIn chose to invest heavily in content authoring and sharing but the core experience was aimed at jobs and resumes. The new mobile app, which was reviewed positively in many cases, changed the focus substantially to these new scenarios.
Discovering features. It is easy to want common features to be easy to use and new features to be discoverable, but those are increasingly at odds as a product evolves. The first challenge is just in finding the screen real estate for new capabilities as discussed above. More likely, however, is that new capabilities will be subordinate to existing ones in terms of surface area. This leads to affordances such as first-run overlays to explain what all the product might do or what gestures are available, which is itself added complexity (and engineering!). One also sees new capabilities with a disproportionate “front and center” placement in an effort to increase discoverability. Often this results from a “marketing” need to drive awareness of the very features being used in outbound marketing efforts.
Over time, A/B testing or usage data will then drive additional change as features are rotated out to make room for new. This all seems quite natural, but also clearly drives complexity or even confusion. This in turn raises the challenge of even changing a product in the first place. Most Google productivity tools we use experience this challenge. Gmail and Apps are increasingly complex and it is getting more difficult to discover capabilities. Historically Google had Labs features to explore new areas and now even Inbox is a whole new experience for mail.
If you ever doubt the ability for people to tolerate more complexity, then just look at the old version of any famous site, app, or program. You’d be amazed at how sparse it is.
Increasing tolerance of complexity. Everyone loves simplicity and certainly every designer’s goal in creating a system is to maintain the highest level of simplicity while providing the right functionality. Over time there is no way to remain simple as more features are added the ability for someone new to the system to command it necessarily decreases and the usage of the system’s breadth decreases. Nevertheless, people become accustom to this growing complexity. It creates a moat relative to new entrants and a barrier to change. People loved the ironically named Chrome browser when it arrived because it was so clean and simple. Few would argue that level of simplicity remains today, yet the complexity is embraced and there’s little opening for a browser that provides less functionality.
For all the criticisms directed at the complexity of Microsoft Office, few switched away to products that do less simply because they were simpler. If you ever doubt the ability for people to tolerate more complexity, then just look at the old version of any famous site, app, or program. You’d be amazed at how sparse it is. The pressure to reduce and simplify comes from everywhere with technology products, but sometimes a failure to embrace a level of complexity can prevent important and strategic change. The most adaptable part of the entire technology stack is the human being at the very top.
Isolating change leads to complex analysis of benefits. UX experience, new or changed, is almost always viewed in isolation. New UX is viewed relative to the small number of initial capabilities and the ease at which those are done compared to existing solutions (i.e. make a voice call on the original iPhone). Changes to products are viewed through the lens of “deltas” as we see in reviews time and time again — reviews look at the merits of the delta, not the merits of the product overall relative to new scenarios that might be more important and old scenarios that might be less important now (as user needs evolve). When viewed in isolation, change is amplified which then makes change more difficult to execute, absorb, or even accept.
Isolation results in intense levels of discussion among the technologists as alternatives are proposed (after the fact) even for very small changes. More importantly, this dialog amplifies the value of small changes which in the scheme of thing will do nothing to improve the business and everything to prevent larger and more strategic changes from happening. Platforms providing horizontal capabilities to broad audiences are notorious for these debates in isolation. Consider the transition iOS made to a new visual design which is now a distant memory.
Competing products and/or changing expectations. The biggest and most important driver for change are the external market forces of competition. Each of the previous drivers are all within your own world view — these are changes you are driving for products you control with inputs and feedback you can monitor. The competitors you view as strategic are incredibly important inputs relative to the longer term viability of the business.
The fascinating thing is that your best customers are the least likely to be worried about your longer term strategy, especially if they have bet their jobs and are empowered by your product. In fact, they will be just as “dismissive” of competing products or new approaches or solutions as your highly paid sales people that are continuing to close deals or the self-taught expert who can’t wait to join the product team. As a technologist you know that your product will be replaced or superseded by a new product and/or technology. It is just a matter of time.
The most important thing to consider is that it is almost never the case that your direct competitor will serve as motivation for changing expectations. The pressure to change will come from unexpected substitutes or newly crafted combinations of a subset of existing capabilities. Ironically, most all of your inputs will come from people and members of the team/company focused on your direct competitor (and the bigger your presence the more likely this will be).
5 Ways To Prepare
The first rules of product design relative to change are to expect it and to prepare for it. It is common-place to remind ourselves in product design that the enemy of the good is the perfect, but relative to evolving experience the enemy of the good is the past.
Assuming that today’s user experience encompasses the value of your product tomorrow is certain to get you in trouble (just as assuming some specific code or API is the core of your value). A comforting way to approach this is to remind yourself that before your current successful user experience there was a successful experience that was widely used. People gave up that product to learn and use your new and different product.
The following are five ways to prepare your design for a future that will require you to change:
- Solve the n+1 problem up front
- Design for the choices you know about
- Optimize only to a point
- Decide your app strategy early on
- Flat is your friend
Solve the n+1 problem up front. One of the most common times a new feature causes UX churn is when you’re adding something you knew about but didn’t have time to engineer. I call this n+1 because across the product there are places where your experience (and code) assumed a finite number of choices and then down the road you find you need one more choice. Commonly this is seen as choices like photo filters, email accounts, team/channels, formatting options, and so on. These changes are recognizable when you go from either no choice to a choice or need to switch from binary/ternary to some list.
The warning signs for this potential change come very early on because you either cut the feature or the feedback is everywhere. It is almost always the case that these are core flows in the experience so designing up front can be a big help. Incidentally, this also holds for engineering and the product architecture where the highest cost additions are often when you need to go back and engineer in a level of indirection to solve for choice where there was no architecture. Some might see this as counter to MVP approaches but nothing comes without a cost.
Design for the choices you know about. As a corollary to above, there is a design approach that says to leave room for the unknown, “just in case”. Such a design often leaves open space in the interface that stares at you like an unused parking spot at the mall. At first this seems practical, but over time this space turns into an obstacle you must work around because nothing ever seems to meet the bar as belonging in the space.
On the other hand, this also serves as a place where everyone on the team is battling to elevate their feature to this valuable “real estate”. Even more challenging, your best fans will have a million ideas for how to fill up this space (and renderings to demonstrate those ideas), and too often that amounts to using it to provide shortcuts to existing functionality. Preparing for what you don’t know by compromising the current does little to postpone the inevitable redesign and does a lot to make the current design suboptimal.
Optimize only to a point. Optimize to a point and recognize that you will change, and assume that the vast majority of input will be focused on areas you were not really expecting (someone on the team probably was expecting but not everyone). In preparing for a future of change one of the most difficult things to do in design is to recognize that where you are at a given point in time for a development cycle is good enough to ship. Stop too soon and the risk of missing is high. Stop too late and the reluctance on the team to change down the road is only increased because of sunk costs and a too much historic baggage.
The most critical rule of thumb in product design is that a product releases “as is” and does not come with all the designs you considered or could consider. When it comes time to disrupt yourself with significant changes, do not underestimate the amount of institutional inertia that will come from a few years of researching and testing every possible alternative to a design. The expression often used, “peacetime generals are always fighting the last war” applies to design and product choices as well.
Decide your app strategy early on. A strategic question facing any broad-based product will be how many mobile apps do you need. In the enterprise if you’re building a full ERP system there’s no way to have a single app, but it could also be very easy to create a sort of app shrapnel and replicate the 1500 legacy web sites that the average large corporation maintains. If your product has either a desktop or web solution and apps are being added, you have to decide early on if your app is a scenario-based companion of the primary/only way you expect people to use a service — you might be considering a mobile capture app to go with a web-based analysis app, or keeping the admin tools on the web to accompany mobile workers in apps.
It is very difficult to switch mindsets down the road so this choice is key. A valuable lesson (in disruption) was learned during the transition from desktop to web. The prevailing broad view that web apps would be supersets of desktop apps proved to be true as many believed, but it just took about three times as long as people thought. If you believe your mobile app is a companion to your site, just be prepared for a large number of customers that only want to access over mobile even if they are not doing so today.
Flat is your friend. Programmers and designers often love hierarchy — hierarchy helps our computer brains to organize and deal with complexity and most techies have no problem navigating hierarchy. Unfortunately most people long ago failed to grasp the Dewey Decimal system and search seems to win out over hierarchical organization in most every instance. Aside from that, the most frustrating changes to experience come when you reorganize a hierarchy (trust me on this one).
Hierarchy is the source of muscle memory and also where much of a sense of mastery comes from. The power users are the people that know where features are hidden or how to drill through panels to find things. Hide and Seek or Concentration are great for the right people, but a poor way to do user experience. A solid approach to avoid a future reorganization is to see how flat you can keep your experience. SEO or A/B testing (or marketing) will always push to keep things above the fold, oddly motivating hierarchy, and not favor scrolling which most everyone understands. The alternative of click/tap to a new place is way more disruptive both today and down the road.
We all wish we could be fully informed about the way we will evolve our product and the way competitors will provide a unique view into the space we are going after. That is never as easy as it could be. The above are just a few ideas to consider if you start from the mindset that once you achieve success you will end up going through a user experience change.
5 Approaches To Avoid
With a successful and deeply used product, when you do make a significant change to your experience the feedback is often swift and clear, and universal praise is exceedingly rare. As a result, the product team discussion will move from expressing frustration to proposing solutions very quickly. Even if you were expecting some pushback, it is never pleasant. At that moment, there is a limited design vocabulary available to make unplanned adjustments, perhaps even more limited than the engineering time you have to execute (assuming that as with most projects you are under pressure to complete all the new stuff).
Similarly, you might anticipate some pushback and are considering a proactive approach with proactive objection handlers or scheduled time for feedback. Regretfully, the solution set is the same since the problem is the change itself, not the way you are changing. The only difference is that the more you engage in defensive engineering efforts the less time you have to get the new work done. More importantly, time spent on salves or bridges only takes away from the existential competitive dynamic that is motivating the need for change.
These potential solutions all arise from the same place, which is that your early adopters, best customers, and front lines sales are all successful with your product and resisting a big change. The resistance is natural — the feeling of empowerment and familiarity. Remember, the reason your are making changes is because your successful product, in your best judgement, is facing an existential threat. This threat is not coming from these early voices, but from the customers you have failed to acquire or are not likely to ever acquire. You are making changes to support future growth not incrementally improving your existing customers.
While the 5 approaches outlined below are typical, they often backfire in predictable ways which is why they should be avoided:
- Add a new mode
- Offer customization
- Solve with a UI level of indirection
- Downplay the changes
- Redesign quickly
Add a new mode. Enthusiasts, marketing, and enterprise customers have no problem with change so long as you add an option they can use to get back to the old way of doing things. This feedback can be pretty sneaky. They will say that the option can be hidden and hard to get to because it is really only for power users or admins, or just an objection handler for the sales process. They might even tell you that you can take away the option after some time to adjust. By the way, another variant of this request is to just provide an option to “hide the new stuff”. You see how this is a sneaky ask — eventually there will be something in the new stuff that even these customers will want but without interfering with the existing “old” way. It certainly seems lightweight enough.
The challenge is twofold. First, once you can get back to the old way of doing things then everyone will want to know why that option exists. “Is the new way not good enough?” will be a common refrain. Second, once you have such an option you are designing for two experiences all the time. Everything you add needs to consider the old way and new way of getting to a new product areas. Not only is this super difficult, it is expensive and it takes away from forward-looking strategic needs. In general, modes, whether user-directed or contextual, are a way to postpone making a strategic choice about the future of your product and advertise your own indecisiveness.
By the way, technology enthusiasts love modes because modality (I suppose dating back to VI) implies hierarchy, control, choice, and a priori knowledge of where your are heading in the product that most people don’t have. Almost all choice and modality is ultimately ignored by customers and when the product magically switches modes, there is almost always a level of frustration that comes from the unexpected behavior changes (even think of the cleverness of having views defined by portrait or landscape which tend to be confusing in practice).
Offer customization. Customization permits you to make big changes with three mitigations.
First, you can allow people to customize your functionality one setting at a time until it returns to where it was. Often this is how a product evolves as it tries to automate previously multi-step processes. For example, if you used to manually turn off the lights at home via some IoT app but then add machine learning to guess, the first time the lights are wrong the answer will be to disable the new automation (AutoCorrect in Word was like this). You need to get something right or handle it gracefully when you’re wrong, but turning it off means it will never be successful.
Second, customization is often used to rearrange the user interface to get it back to where it was before when it was good Maybe you took away a share button to use the one provided by the OS or maybe you added a few tabs to the top level UI, well then just a switch to move things around.
Third, customization can be used for when you want to add something and the team can’t even decide whether it is a good idea or not so you add your own way to turn it off or hide it. All of these have the same downstream problems with setting a risky precedent that can’t be maintained (i.e. everything new comes with a way to change it) and adding combinatorics that can’t be managed (the testing matrix).
Making up your mind is the best approach. Longer term, the disruptive innovation will come from when the new product subsumes your product and at that time customizing how your product works will prove to be extraordinarily low-level, almost like a debugger. Think this will never happen, then look at all the options in Office that we totally sweated over. Again, technologists love customizations so you are almost certain to get positive feedback and strong encouragement to providing customization.
Solve with a UI level of indirection. The hamburger, Tools|Options, right click, sub-menus, and more are all ways of adding things without adding things or hiding things you add but don’t want to add. There’s no magic answer to where to squeeze all the things you need in a design into a (very) finite space, but for sure if you find yourself putting something new behind a level of indirection then think twice.
Once you think you can get away with “change” by putting it behind a level of indirection then you might as well not do it. Sometimes this type of approach takes place in enterprise products where you are responding to a competitive dynamic but you don’t agree with the competitor or the competitor’s approach is at odds with your overall design. The theory is to add the checkbox but not break your overall model or experience. Only you can judge whether you are seeking credit with reviewers and analysts or actual humans but be careful thinking that you have solved the problem and not just created a future problem.
The discoverability of your work hidden behind a level of indirection is minimal so always ask if you’re doing the work for customers or to make yourself feel like you’re addressing a business or customer need.
Downplay the changes. If you go through the work to understand why you are going to make a big change, then design and engineer a change, the very worst strategy is to downplay the effort when it comes time to communicate what you did.
If you make a big change and talk about it like it is a little change then many will wonder if you are confused and/or lack empathy. The challenge is that this one is the easiest of all responses since it is simply a different tone or wording in a post describing what is changing. You choose the right screen shots or feature names and things can look more familiar. When customers who were expecting the same or incremental see what you’ve done this tends to increase the backlash and the internet loves a good dose of corporate “wool over the eyes of customers”.
Since significant strategic challenges are driving this change, backing off is a worst of all worlds reaction — you send the message to the market that you’re fighting the last war, thus not engaged in the future, and customers come to expect that as well.
Redesign quickly. If how you communicate the change is the short term response, then the medium term response is to quickly redesign what you just spent a lot of time designing. How quickly can you back out the most egregious changes? How can you undo things with as little engineering work as possible? What if you just added a couple of old things back front and center? These are all things that will be rapidly floated within the team.
The most fascinating aspect of this response is that this is what the internet will do for you, both quickly and broadly. The reason is that once a new design is put forth, incremental changes to that design along the lines of “do this instead” will be offered by the community that is empowered by your product. There will almost certainly be good ideas amongst all of these, and even more likely they will be alternatives you considered (we never really learned why Apple so steadfastly refused to highlight the shift state on the iOS keyboard but it is impossible to believe this was not discussed).
Design and engineering are difficult and we all know that the likelihood of mistakes increases with the pace of reactionary change.
Reality
As this post keeps saying, the reason it is so painful and frustrating to change user experience is because right at the moment that your product has successfully reached the point of being empowering and critical to the jobs and lives of your customers it is also facing the most existential competitive and marketplace challenges.
The reality is you have to respond to the marketplace. You can choose to continue to iterate on the same path with the same customers. In the technology world that is, with as high a certainty as you can count, focused on the shrinking market. Disruption is real and it so far it is proving to be much more of a law than a theory.
Is the time to change right? Is the design you chose the right one? Are you focused on the right strategic competitors? The other reality of technology change is that most often the forces that keep a product and company from transitioning from one generation to the next are not an understanding or ability to debate these choices, but the ability to execute across product, engineering, marketing, and sales.
The really good news about all of this is that if you can create the product change and go-to-market execution, the reality is that short-term memory is a real thing, especially in a growing market. If you can make changes that secure new customers and grow or that your typical customers can adjust to without “incident” then there’s a really good chance that memory will be short term.
Those customers that chose to stick with character interfaces or would not move off a web app, got left behind by graphical and mobile users. This happens with every technology platform shift and happens within every category. Growth is the friend of change and if you’re not growing you are by definition shrinking.
I’d like to add one last reality for everyone who both made it this far and is out there critiquing new designs for products they use and love. The people working on products you love are on average as good as you, as thoughtful as you, and as informed as you. They are all open to feedback and good two-way discussion. Treat them the way you would like to be treated in the same situation.
—Steven Sinofsky (@stevesi)
Author’s note. I’ve never used a music lyric quote and don’t mean to steal Ben’s intro, but this quote from this song has special meaning to me in this particular situation.
This post originally appeared on Medium.




 When I received my new 9.7” iPad Pro I decided to break tablet tradition and personalize it with stickers, just as I’ve done on laptops (and my Surfaces) for years. I did so because I began with the mindset that this iPad would replace my laptop(s) for full time use (here laptop means my Surface(s), Yoga, MacBook, and desktops). It has been almost a month and that is exactly what happened. My sticker investment paid off. I don’t feel like I’m forcing myself into this mode of working, but rather I am more productive, futz way less with my “computer”, and find many things easier. Work is different, but better.
When I received my new 9.7” iPad Pro I decided to break tablet tradition and personalize it with stickers, just as I’ve done on laptops (and my Surfaces) for years. I did so because I began with the mindset that this iPad would replace my laptop(s) for full time use (here laptop means my Surface(s), Yoga, MacBook, and desktops). It has been almost a month and that is exactly what happened. My sticker investment paid off. I don’t feel like I’m forcing myself into this mode of working, but rather I am more productive, futz way less with my “computer”, and find many things easier. Work is different, but better. In
In  AJ Shankar was busy working on his PhD thesis at the University of California, Berkeley in the prestigious Programming Systems Lab, where he published a number of important papers in OOPSLA and PLDI. As a big fan of side projects, he also caught the maker bug.
AJ Shankar was busy working on his PhD thesis at the University of California, Berkeley in the prestigious Programming Systems Lab, where he published a number of important papers in OOPSLA and PLDI. As a big fan of side projects, he also caught the maker bug.












 Flymotion’s complete Police surveillance drone system.
Flymotion’s complete Police surveillance drone system.








 Sony short throw project. Image is about 100″ projecting from the floor console about 12″ from the wall.
Sony short throw project. Image is about 100″ projecting from the floor console about 12″ from the wall.











 Taylor Rosenthal, CEO and Founder of Recmed.
Taylor Rosenthal, CEO and Founder of Recmed. When it comes to innovation and roadmaps there’s nothing special about the start of a new calendar year other than a convenient time to checkpoint the past year and to regroup for the next. Everyone’s feeds are going to be filled with “best of”, “worst of”, and “predictions” for 2016 and those are always fun. What I’ve always found valuable is taking a step back and thinking about the themes that will impact decisions at the product and business level over the next year.
When it comes to innovation and roadmaps there’s nothing special about the start of a new calendar year other than a convenient time to checkpoint the past year and to regroup for the next. Everyone’s feeds are going to be filled with “best of”, “worst of”, and “predictions” for 2016 and those are always fun. What I’ve always found valuable is taking a step back and thinking about the themes that will impact decisions at the product and business level over the next year. A key role of product management (PM), whether as the product-focused founder (CEO, CTO) or the PM leader, is making sure product development efforts are focused. But what does it mean to be focused? This isn’t always as clear as it could be for a team. While everyone loves focus, there’s an equal love for agility, action, and moving “forward”. Keeping the trains running is incredibly important, but just as important and often overlooked is making sure the destination is clear.
A key role of product management (PM), whether as the product-focused founder (CEO, CTO) or the PM leader, is making sure product development efforts are focused. But what does it mean to be focused? This isn’t always as clear as it could be for a team. While everyone loves focus, there’s an equal love for agility, action, and moving “forward”. Keeping the trains running is incredibly important, but just as important and often overlooked is making sure the destination is clear.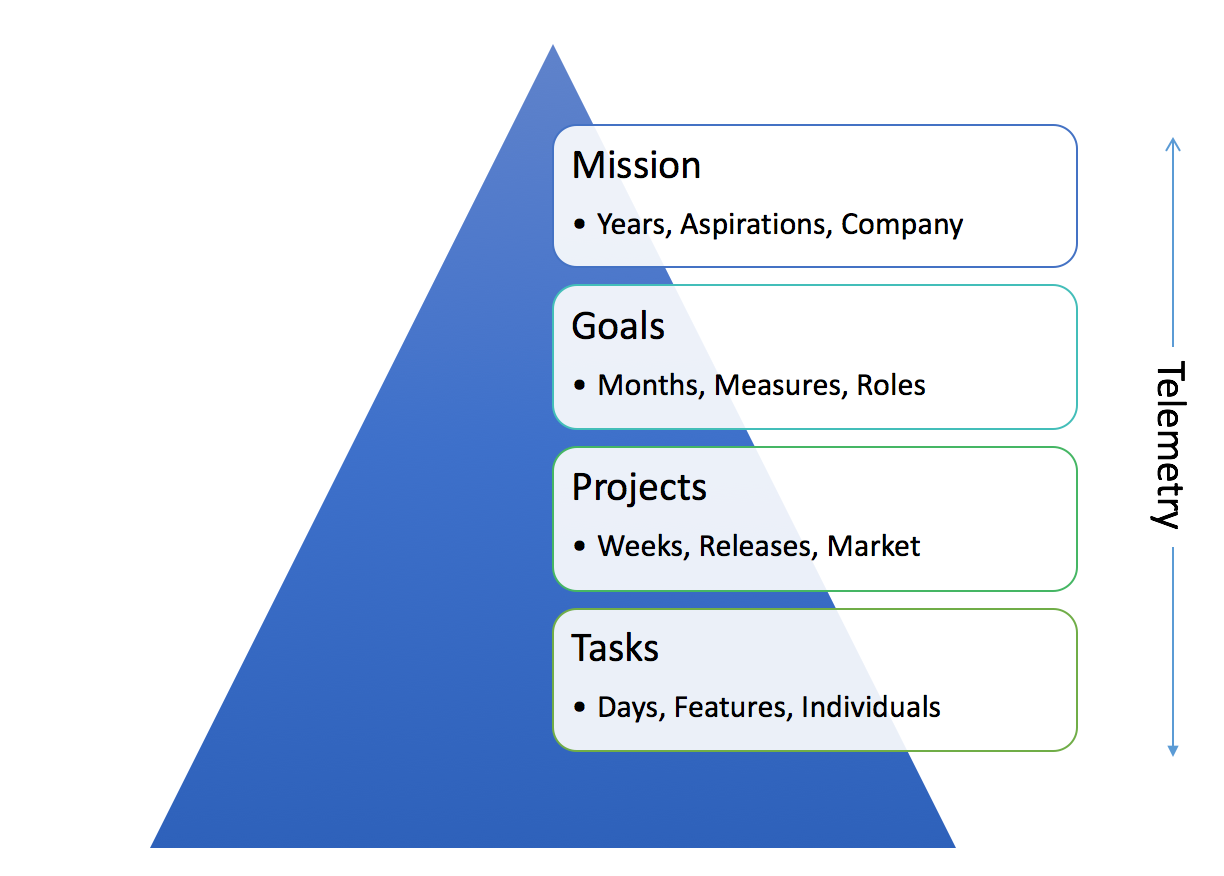

 Decision-making is one of the most difficult skills to master as a manager. A startup CEO literally sees a constant stream of decisions to be made: from hiring and firing, to Android or iOS, all the way to Lack or Billy. As the company grows to 10–20 people (usually mostly engineering) the bonds and shared experiences continue support decision-making at the micro-level. Once a team grows larger there is a need for management and delegation. While growth is a positive it also a stressful time for the company and founder/CEO.
Decision-making is one of the most difficult skills to master as a manager. A startup CEO literally sees a constant stream of decisions to be made: from hiring and firing, to Android or iOS, all the way to Lack or Billy. As the company grows to 10–20 people (usually mostly engineering) the bonds and shared experiences continue support decision-making at the micro-level. Once a team grows larger there is a need for management and delegation. While growth is a positive it also a stressful time for the company and founder/CEO.

